Introduction to MLOps
The era which undoubtedly belongs to Artificial Intelligence results in the use of ml in almost every field. Whether it is healthcare, business, and technical, it is everywhere. The availability of the latest ML tools, techniques, algorithms, and platform to develop Machine Learning Models to solve a problem is not a challenge. The real challenge lies in the maintenance of these models at a massive scale.
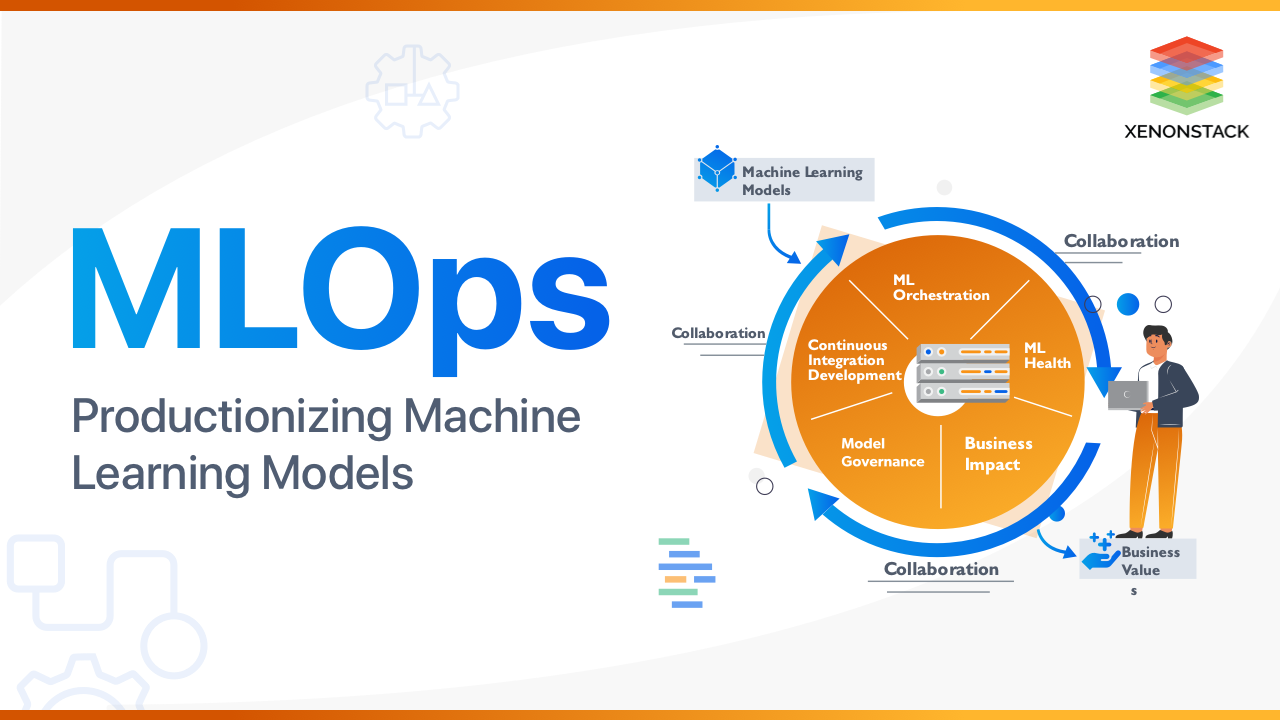
This blog will give an insight into Productionizing Machine learning models with MLOps Solutions. The new chasm of the development process of ml involves the collaboration of four major disciplines - Data Science, Data Engineering, Software Engineering, and traditional DevOps. These four disciplines have their level of operations and their requirements with different constraints and velocity.
A branch of ML that focuses on creating and implementing machine learning models on low-power, small-footprint microcontrollers such as the Arduino.Click to explore about our, MLOps for Scaling Tiny ML
What is MLOps?
It is the communication between data scientists and operations teams. It have mixed data scientists and services designed to provide automation in ML pipelines and get more precious insights in production systems. It provides reproducibility, visibility, managed access control, and the computing resources to test, train, and deploy AI algorithms to Data engineers, business analysts, and operations teams.
Why is it important?
It is pretty clear from the above content that the need for it and what lead to the rise of this hybrid approach in the modern era of Artificial Intelligence. Now moving forward from ‘What’ to ‘Why.’ Let us give some light on the reasons which led to the use of it in the first place.
Orchestration of multiple pipelines
The development of machine learning models is not a single code file task. Instead, it involves the combination of the different pipelines, which have their roles to perform. Pipelines for the primary process such as pre-processing, feature engineering model training and model inference, etc. involved in the big picture of the ml model's development. It play an essential role in the simple orchestration of these multiple pipelines to automatically update the model.
Manage Full Life Cycle
The ML lifecycle model consists of different sub-parts that should be considered a software entity individually. These sub-parts have their own need for management and maintenance, which DevOps often handle, but it is challenging to manage them using traditional DevOps methods. It is the newly emerged technique that includes people, processes, and technology that give an edge to swiftly and safely optimize and deploy ml models.
Scale ML Applications
As it is said earlier in the topic, the development of models is not an issue to be worried about, and the real problem lies in the management of the models at scale. The management of thousands of models at once is a very cumbersome and challenging task that tests the performance of the models at scale. With the use of it is a natural scale that manages thousands of pipelines of production models.
Maintain ML Health
Maintaining ML health after the deployment of ML models is the most critical part of the post-process. It is vital so that ML models can be operated and managed flawlessly. It provide the latest ML health methods by enabling the detection of different drifts (model drift, data drift) in an automated way. It can provide the ability to use the latest edge cutting algorithms in the system to detect these drifts so that these drifts can be avoided much before they start to affect ML health.
Continuous Integration and Deployment
Continuous Integration and Deployment is one of the sole purposes, which led to DevOps' use in any software product development procedures. But due to the scale of the operability of ML models, it is difficult to use the same methods of continuous integration and deployment, which are used for other software products. It can provide the hands to use different dedicated tools and techniques that are specialized to ensure the continuous integration and deployment services in ML models.
The debate about Continuous Integration vs Continuous Deployment has recently been the town's talk, and there are quite mixed thoughts on which one is better. Click to explore about, Continuous Integration vs Continuous Deployment
Model Governance
Under Model Governance, It can provide rich model performance data by applying it to monitor the attributes at a massive scale. It can also provide the ability to take snapshots of the pipelines for analyzing critical moments. The logging facilities and audit trails under it can also be used for reporting and continuity of compliance.
What are the Challenges of Productionizing ML models?
Listed below are the common challenges organizations face while productionizing the Machine Learning model into active business gains.Dataset Dependency
Feeding the data to training and steps done at the evaluation stage in the data scientist sandbox can dramatically vary in real-world scenarios. Depending on the use case, data changes with time, and lack of regularity cause poor performance of ML models.Simple to complex pipelines
Training a simple model and putting it into inference, and generating prediction is a simple way of getting business insights. This usually a manual offline training and then use the trained model to generate inference. But mostly in business problems, this is not sufficient. In real-world cases, regularity is needed, and with time models need retraining on new data. A retraining pipeline needs to add to the system that frequently gets the latest data from the Data Lake. There will be many models in the retraining pipeline, and human approval is needed to decide which model to choose for production. In other cases where ensemble models are used to improve accuracy, multiple training pipelines are used, and in the Federated pipeline, it becomes even more challenging to maintain.Scalability Issues
There are scaling issues at different development levels, and Even if the data pipeline is developed in a scaled way, issues come while feeding the data to ML models. Because ML models are built in a Data scientist sandbox. It was not developed to take scalability in mind; rather, it was developed to get good accuracy and the right algorithm. Building different types of ML frameworks to use, and each has its scaling and opportunities issues. On the hardware side, Training, a complex neural network, requires a powerful GPU, and simple ML models can be processed on a cluster of CPUs.Production ML Risk
The risk of ML models not doing well is continuous and needs continuous monitoring and evaluation if they are performing within the expected bound. On live data, metrics like Accuracy, Precision, recall, etc., cannot be used as live data does not have labels. To ensure the health of ML models, different methods such as Data Deviation Detection, Drift Detection, Canary Pipelines, Production A/B tests should be used.In 2022, Organizations expect to have an average of 35 AI or ML projects in place. Source: Gartner Inc.
Process and Collaboration
ML requires multiple abilities to handle production-grades ML systems like data scientists, data engineers, business analysts, and operations in production. Different teams will focus on various outcomes. A data scientist will improve accuracy, detect data deviations, and business analysts want to enhance KPIs. In operations team wish to see uptime and resources. Unlike the Data scientist sandbox, the production environment has many objects like models, algorithms, pipelines, etc., that are difficult to handle and versioning of these is another issue. Object storage is needed to store the ML models, and a source control repository is not the best option.
How is it different from DevOps?
- Data/model versioning != code versioning
- Model reuse entirely has a different case than software reuse, as models need tuning based on scenarios and data.
- Fine-tuning is needed when to reuse a model. Transfer learning on it, and it leads to a training pipeline.
- Retraining ability requires on-demand as the models decay over time.
MLOps in Azure
Azure MLOps for ML enables data science, and IT teams to collaborate and increase model development and deployment speed while monitoring, validating, and governance of machine learning models.- Training model for reproducibility with advanced tracking of datasets, experiments, and code.
- Autoscaling, no-code deployment, powerful managed to compute, and tools for quickly model deployment and training.
- Efficient workflows with scheduling and management capabilities to build and deploy with CI/CD.
- Advanced capabilities for governance and control objectives and promote model transparency.
MLOps in AWS
AWS MLOps (Machine Learning Operations) helps streamline and enforce architecture best practices for ML model production. It is the extendable framework that provides a standard interface for managing ML pipelines for AWS ML services and other services. AWS template allows customers to upload their trained models, configure the pipeline, and monitor their operations. This increases the team's agility and efficiency by enabling them to repeat successful processes at a large scale.- Initiates a pre-configured pipeline through an API call or a Git repository
- Automatically deploys a trained model and provides an inference endpoint.
- Supports running integration tests to ensure the deployed model meets expectations
- Allows the provision of multiple environments to keep the Machine Learning model's life cycle.
- Notifies users about the pipeline outcome via email.
MLOps in GCP
Data scientists and ML engineers are trying to apply DevOps principles to ML systems. It is an ML engineering practice that aims to unite Machin Learning system development and ML system operation. It helps automation and monitoring at all ML system construction steps, including integration, release, deployment, infrastructure management, and testing.
Characteristics of MLOps GCP (Google cloud platform):
- Rapid experiment: ML experiment steps are orchestrated, which automate the transition between steps and lead to the rapid iteration of experiments and better production readiness.
- Experimental-operational symmetry: The critical aspect of its practice for uniting DevOps is implementing a pipeline used in the development or experiment environment or used in the preproduction and production environment.
- Continuous delivery of models: An ML pipeline in production continuously delivers services to new models trained on new data. The model deployment step is automated, which serves the trained and validated model as a prediction service.
- Pipeline deployment: Helps to deploy a trained model as a prediction service for production. The whole trained pipeline is deployed, which automatically and recurrently runs to serve the trained model.
What is the Workflows of Machine Learning?
The workflow of an ML project includes all the below-given steps to build the proper ML project from scratch.Reproducibility in ML models
For fault tolerance and iterative filtration of ML models is essential, and for that, reproducibility is needed. Repeatability required to illuminate the source of variation like -- Inconsistent hyperparameters
- Change to model architecture
- Random initialization of layers weights
- Shuffling of datasets
- Noisy hidden layers
- Change in ML frameworks
- Cpu multi-threading
- Non-deterministic GPU-floating point calculation
Feedback
There should be a feedback loop that should be analyzed by the model monitoring system and generate feedback on the model performance. It should be there to check if a model is performing wrong due to data drift.The system needs continuous learning and training from the real world. Click to explore about, DevOps for Machine Learning , Tensor Flow and PyTorch
ML Operations
Controllability
When it comes to controlling the production updates, it's really difficult in ML pipelines as there is not only the source code that changes in the pipeline, but when a new retrained model is selected by human approval or some advanced auto-selection method, The new changes should be done with proper control of not having any instability or downtime of ML applications.Automation
ML pipelines are code, and the DevOps toolchain pipeline plays an essential role in it. The source code repository automation facilitated by Jenkins and orchestrators such as AirFlow is a classic example. But when it comes to ML pipelines, there are additional challenges that the typical traditional toolchain cannot address. Like ML pipeline can have parallel running multiple pipelines, There are interdependencies like Model Approval and Drift Detection. These additional dependencies need to be integrated with the DevOps toolchain pipeline.Model Management
Model Management is the core of it. When it comes to managing complex pipelines where a large number of models, objects, and training pipelines are generated, MLOps are needed.Model versioning
Making changes reversibly is necessary for production for stability and fault tolerance. Unlike source code versioning of ML models is an additional step from the traditional pipeline.Model tracking
Complex pipelines of models lead to many models runs in the pipeline, like in the ensembles models run. Creating this many experiments to select the best champion or challenger model requires model tracking. There are different kinds of tools like MLflow available for tracking models, or one can build a custom pipeline according to the use case.ML Monitoring
Monitoring in ML systems is not just checking the uptime of different services and resources/compute it's taking. ML brings things to monitor that is directly related to the success of business outcomes as in production.ML data drift
The change in the relationship between input and output data with time called data to drift. The data drift analysis should be in the ML monitoring. The observability of data drift is essential to analyze if retraining requires any changes in the configuration of ML models. That is the reason why inference monitoring is needed. Let’s discuss inference monitoring in brief.Inference Monitoring
Continuously monitor the inference and observe if it is behaving according to the expected bounds. This monitoring tells about mismatching of input and output data, which detects data drift. It also provides the performance of the ML model using which performance analysis and comparison of the models is possible.What are the best practices for Productionizing ML Models?
Implement continuous integration (CI), Continuous Delivery (CD), and retraining the pipeline for a ML model using different DevOps services and Machine Learning ServicesML Workflow
Version source code- Git
Version Artifacts/Models
- S3
- Minio
Package Models for Reproducibility
Provision infra as code- Compute targets
- Workspace
- Datastores
For New Code
- Unit tests
- Data quality checks
- Train model
Components Required
- ML Service
- ML Compute Tools
- Machine Learning Pipelines
Storage Components
- Containers Components (to run and store different Image components)
- Production Components (such as Kubernetes services)
- Application Components (includes monitoring services)
A complete platform where we can perform model building, validation, versioning, serving and deployment of ML models. Click to explore about, Machine learning Platform for Training and Serving
Machine Learning Operations
- Define the process of observability
- When failure occurs, it should be easily detectable, set alerts.
- Check If the model is wrong. Does it have a feedback loop?
- Check how does it scale - does it have an automatic load balancing.
- Unit test
- Data test
- Train the model
- Evaluate model
- Register model
- QA environment
- Production environment
- Model Artifact trigger
- Building an image of scoring
- Deploying on Container Instances
- Test web service
What are the benefits of enabling MLOps?
- Scale ML Models initiatives broadly by swiftly and flawlessly converting the true potential of machine learning into business processes (which already exist) and systems (which exist across the enterprise)
- It provides the advantage to strap and increase investments in existing ML and data science tools and technology to the maximum and create a consolidates, a system of maintaining the records in between different teams and different projects.
- It helps to manage and maintain data science and IT/Ops teams' partnership to work together to provide ML-powered applications that can provide some value in results.
- It helps to minimize the hazard to the organization by regularizing and importing in place hefty governance documentation and balances and by enabling the use of best practices for ML models at the production level.

Conclusion
Machine Learning grows with ML research applied to business solutions. MLOps helps deploy ML models within minutes rather than weeks and enables them to achieve a far faster value result than with homegrown deployments
- Discover more about ML Pipeline Deployment and Architecture
- Click to explore our Artificial Intelligence Services and Solutions


