Overview of DevOps Platform
DevOps is a platform that reduces the space between Dev that is Development Team and Ops that is Operation Team to reduce the systems development life cycle. We can say that DevOps Engineering is a methodology or practice which is used for system scaling. It is an infinite loop because, in this, every stage work in continuous form. This article will give an insight about GCP DevOps Pipeline Implementation and Deployment.
The pipeline is a method or technique of decomposing a sequential process into a subprocess. In this, each sub-process is executed in a particular segment that operates it concurrently with another segment.Pipeline is a set of data process element which is connected in series. The pipeline is divided into a different stage, and these different stages are combined to form a pipe-like structure.
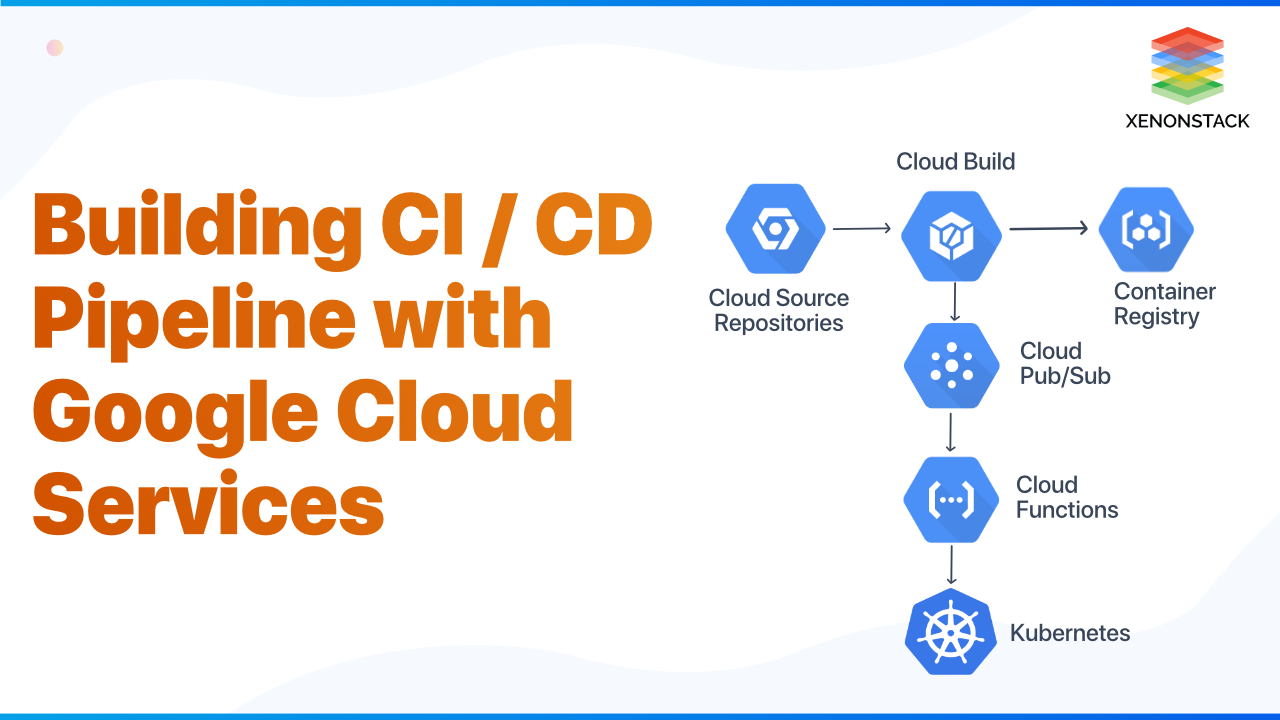
Building a GCP DevOps Pipeline
DevOps pipeline is set up in a software project that helps to deliver continuous integration, continuous deployment, and eventually find the continuous Delivery of the project. The main idea behind pipeline is too able to create a reliable and repeatable system and able to continuously improve the process of software development and Delivery to make software delivery faster.
What is Continuous Integration?
It is a software development life cycle. It builds your application continuously. Basically, in this continuous integration server, compiles the code, validate the code, and review the code, Unit testing, Integration testing, and packaging the application.
- Unit testing is a testing of each part of the code.
- Integration testing is how different parts of codes work together.
How Continuous Integration Works?
This pipeline is a logical representation of how the software will move along various phases and stages in this life cycle - In the first phase of the pipeline, developers put their code, and then code goes into the version control system. Having a proper version tag, if we have any error, we can go to the particular version and then check the code. After the version control is done, then it goes to the build phase where code is taken from the version control system then it is compiled. The code of all the features is merged, and then it is compiled together.
Once the code is compiled, then it goes to testing where unit testing takes place. We break the complete software in small chunks based on a different path. It is divided into small units to understand how it works after this Integration testing take place, where it assures that all the integrated way can work together or not. After testing, the code is sent to the deploy phase, where the software is deployed on a test server where you view the code. If there is an error in testing, then code is sent back to the development team, they fixed it and then sent back the code again to the version control.
Enterprise Agile DevOps Solutions play a crucial role in the successful implementation of continuous deployment and delivery practices by facilitating collaboration, automating processes, and providing visibility to empower organizations to deliver high-quality software faster and more efficiently.
What is Continuous Deployment?
Continuous deployment is a plan for a software release, where every code passes through the automated testing phase. It is automatically released into the production environment, making changes that are visible to the software' s users. With Continuous Deployment, every move that is made in code deploys to production automatically. This methodology works well in project environments where you can plan to use the user as the actual tester, and it can be quick to release.
What is Continuous Delivery?
Continuous Delivery is the potential or ability to change all the types that are including new features, configuration changes, bug fixes into production, or the hands of users, safely and quickly, in an environment-friendly way. Continuous Delivery is a small raise cycle with short sprints, where the goal is to keep the code in a deployed state at any given time. It does not mean that your project or code is 100% complete.
What is GCP DevOps Pipeline?
Google cloud is a group of cloud computing services that runs on the same infrastructure, which is used by Google for its end-user products, such as Google Search and YouTube.it provides a series of standard cloud services including computing, data storage, data analytics, and machine learning.
Deploying a pipeline on Google Cloud
Google cloud platform services such as compute engine and cloud storage are managed by cloud dataflow service to run your cloud dataflow job. The execution parameter specifies whether the steps of the pipeline run on worker virtual machines or works locally. To manage GCP resources, the Cloud Dataflow service performs and optimizes many aspects of distributed parallel processing automatically.These include -
- Parallelization and Distribution - In this Cloud, Dataflow partitions your data automatically and distribute your worker code to Compute Engine instances for parallel processing.
- Optimization - In this Cloud, Dataflow uses your pipeline code to create an execution graph that represents your pipeline's collection and transforms and optimizes the graph to the most efficient performance and resource usage. Cloud Dataflow also maximizes your possible operations cost, such as data aggregations automatically.
- Automatic Tuning - The Cloud Dataflow service contains several features that provide immediate adjustment of resource allocation and data partitioning, such as Auto scaling and Dynamic Work Rebalancing. This feature helps the Cloud Dataflow service to execute the job as quickly and efficiently as possible.
Pipeline lifecycle, conversion from pipeline code to Cloud Dataflow job When the cloud dataflow program runs, the cloud dataflow creates an execution graph from the code, which creates your pipeline object. It includes all the transform and their similar processing functions. This phase of activity is known as Graph Construction Time. During Graph Construction, cloud dataflow checks for various errors, and it ensures that your pipeline graph doesn't contain any illegal operations. Then, the execution graph is express into JSON (JavaScript Object Notation) format, and then the JSON execution graph is transmitted to the cloud data flow graph.
After this JSON execution graph is validated by cloud dataflow service, the graph becomes a job on the cloud dataflow service once the graph is validated.By using the cloud Dataflow Monitoring Interface, we will be able to see our job, its execution graph, status, and log information. In Java: SDK 2.X, the Cloud Dataflow service feeds a response to the machine where you ran your cloud dataflow program. This response is compressed in the object Dataflow Pipeline Job.
DevOps assembly lines, particularly in the context of GCP DevOps Pipeline, offer organizations a powerful framework for streamlining their software delivery process. By leveraging continuous deployment and delivery practices, along with the automation and collaboration capabilities, organizations can accelerate their software development lifecycle and deliver high-quality applications faster and more efficiently.
Implementing Execution graph for GCP DevOps Pipeline
In this, the graph of steps is built by cloud dataflow that represents the pipeline, and It is based on the transforms and data that is used by the user when the user construct their pipeline object. This is call pipeline execution graph. The execution graph frequently differs from the order in which we specified our transforms when you construct the pipeline. This is done because the Cloud Dataflow service performs various optimizations and fusions on the execution graph before it runs or managed cloud resources. The Cloud Dataflow service regards data dependencies when executing the pipeline. However, the steps without data dependencies between them might be performed in any order.
Parallelization and distribution
The cloud dataflow service distributes and parallelizes the processing logic in the pipeline to the worker you have allotted to perform the job. The concept in the programming model is to represent parallel processing functions that are used by cloud dataflow.
Exception for GCP DevOps Pipeline
An exception is unwanted events which required in a change in the flow of control. Generally, limitation arises within the CPU. Characteristics of Exception -
- If an exception occurs in the same place with the same data and memory allocation is known as an asynchronous exception.
- Devices external to CPU and memory causes an asynchronous exception.
- If the exception is a mask than hardware will not a response to the exception.
- If the exception is not unmasked, then the hardware will respond to that exception.
Exception in GCP DevOps Pipeline
When one instruction has been executed by the processor, when you have an exception generated by that instruction you have to stop the program and then execute the exception depending on what the exception handler does, you have to terminate your program or resume the program. If the program is resumed, then you have to save the state of the program. In pipeline implementation, you have to flap the execution of multiple instructions. When there are many instructions are there is a program, and one of them raises an exception. It becomes much more challenging to handle.
Implementing the CALMS DevOps Framework can help organizations navigate their DevOps transformation journey successfully. By focusing on culture, automation, lean practices, measurement, and sharing, organizations can create a collaborative and efficient software development and delivery process that drives innovation and delivers high-quality software faster.
Handling Exception in the pipeline
When an exception has been recognizing or occur in the pipeline, so we put a trap instruction into the pipe on the next instruction fetch. Until the trap instruction takes off. Making sure that all writes for faulting instruction as well as the instruction which follows the faulting instruction are turned off. This is done by placing Zero in the latches and prevent any state changes until the exception is handled.
Fusion Optimization for GCP DevOps Pipeline
Once JSON forms the pipeline execution graph is validated, then the cloud dataflow service may do modification to the graph to perform optimization. In single steps, optimization can transform into the pipeline execution graph or can include fusion multiple steps. Fusion prevents the cloud dataflow service. Prevention from fusion We can prevent a fusion by adding an operation to the pipeline that forces the cloud dataflow service to arise your intermediate. We can use the following operations -
- By inserting a group by key and ungroup after your first ParDo.
- Bypassing the intermediate collection as a side input to another ParDo.
Enabling Autoscaling in Google Cloud DevOps Pipeline
Autoscaling is important part of DevOps Culture enables the Cloud Dataflow service automatically, and it chooses the appropriate number of worker instances required to run the job. The Cloud Dataflow service may be effectively re-allocate more workers or fewer workers during runtime to account for the characteristics of the job. Autoscaling is enabled by default on all batches, and Cloud Dataflow jobs are created using the Cloud Dataflow SDK.
Streaming Engine in Google Cloud DevOps Pipeline
As in this cloud, the dataflow pipeline runner executes the steps of the streaming pipeline on virtual machines and consumes CPU, memory, and Persistent disk storage of workers. The streaming engine moves pipeline execution out of the user's virtual machine. Benefits of Streaming Engine -
- It reduces the consumed CPU, memory, and Persistent Disk storage resources on the user's VMs.
- Streaming Engine offers smooth and granular scaling of users.
- It Improves supportability.
A process and balanced organization approach for improving collaboration, communication among development and operation. Click to explore about, Best Open Source DevOps Tools
Summarizing GCP for Continuous Delivery
DevOps is a platform in which the Development Team and Operation Team comes together to reduce the software development cycle. The pipeline is a method or technique of decomposing a sequential process into the sub process. DevOps pipeline is a setup in a software project that helps to deliver continuous integration, continuous deployment, and continuous Delivery. Continuous integration builds the application continuously. Continuous integration has a different stage for its working that is version control, build, unit testing, deploy, auto testing, deploy to production, measure validate. Continuous deployment is a plan for the software release. Continuous Delivery is the ability to change all the types that is including new features, configuration changes, and bug fixes into production. Cloud Computing provides permission to create, configure, and customize business applications online.
All Day DevOps is a renowned global conference that brings together professionals from the DevOps community for a full day of learning and networking. This conference is dedicated to exploring the latest trends, technologies, and best practices in DevOps, providing valuable insights and knowledge that can help organizations optimize their software development and delivery processes.
- Learn about the AWS DevOps Services
- Discover, The Role of Virtualization in DevOps
- Explore the Difference, ITIL vs DevOps


