
Kubernetes - A Container Orchestration Platform
In today's rapidly evolving digital landscape, the demand for cloud computing is skyrocketing. Whether it's a small startup or a large enterprise, organizations are striving to ensure that their resources and data are accessible anytime, anywhere. However, this level of availability comes at a cost. The traditional approach of installing physical machines everywhere and managing data across multiple locations is not only expensive but also inefficient.
Fortunately, the advent of cloud technology has revolutionized the way businesses operate. With cloud computing, organizations can seamlessly access and utilize resources without any geographical limitations. Major cloud providers like AWS, Google, and Microsoft Azure have paved the way for this transformation. Along with the cloud, other concepts such as containers have emerged as game-changers in the industry.
PostgreSQL is a powerful, open-source Relational Database Management System. Click to explore about our, PostgreSQL Deployment in Kubernetes
This is why the cloud came to light. With the cloud, everything was readily available and could be used by any business, small or big, without worrying about the things mentioned above. The major cloud providers AWS, Google, and Microsoft Azure. A few more concepts came with the cloud, such as images, containers, etc. Let's talk about containers. What are these? So, in simple words, reliable in any computing environment.
Yes, Containers provide us with many things, but they also need to be managed and linked to the outside world for other processes such as distribution, scheduling & load balancing. This is done by a container orchestration tool like Kubernetes. So, when we talk about containers, KUBERNETES comes attached. Maybe I'm wrong, but within the past few years, it has made its place in this cloud world as a container orchestration tool. It is built by google as per their experience in using containers in production. And Google has made sure that it is the best in its field.
Discover more by reading the blog:
- Learn what Kubernetes is and why it's important for container orchestration.
- Discover the benefits of using Kubernetes, such as portability, flexibility, and multi-cloud capability.
- Understand the basics of Kubernetes architecture, including nodes, pods, and services.
- Explore best practices for Kubernetes monitoring and management.
What is Kubernetes?
It is an open-source container orchestration engine and also an abstraction layer for managing full-stack operations of hosts and containers. From deployment, Scaling, Load Balancing and to rolling updates of containerized applications across multiple hosts within a cluster. It make sure that your applications are in the desired state. Kubernetes 1.8 released on September 28, 2017, with some new features and fulfill the most demanding enterprise environments.
There are now new features related to security, stateful applications, and extensibility. With Kubernetes 1.7 we can now store secrets in namespaces in a much better way, We ‘ll discuss that below.
Experience the unified management and governance for your on-premises, edge, and multicloud Kubernetes clusters. Deploy and scale containers effortlessly with Azure Kubernetes Services
Why do we need Kubernetes?
There are several reasons listed below:
1. Moving from - Monolith to Microservices
Monolith applications are described as single-tiered applications in which different components are packaged together to form a single platform. It's been used for years and is still in use for its easy-to-develop and deploy characteristics. But it has some drawbacks and limitations. So, people are moving towards microservices as an alternative to monolithic applications.
Microservices are an application development technology that produces an application based on highly distributed services as an iterative process of the service-oriented architecture and design style. In contrast to monolithic architecture, Microservices architecture takes a modular design instead of combining all information in a single platform.
2. Increased Usage of Containers
The Application Container business is rapidly growing yearly, reaching USD 7.6 billion by 2026, increasing to USD 1.5 billion in 2020. This rapid growth is mainly because of the advantages containers provide for development teams, such as agility, portability, development speed, efficiency, easy management with fault isolation, and high security.
3. Managing a large number of Containers
Container orchestration methods provide a structure for scalably managing containers and microservices architecture. For container life-cycle management, there are multiple container orchestration tools. Docker, Kubernetes, and Apache are a few popular choices.
It enables the creation of application services that involve multiple containers, the scheduling of containers across a group, the scalability of those containers, and the management of their health over time. Manage everything from software deployments to infrastructure

An open-source system, developed by Google, an orchestration engine for managing containerized applications over a cluster of machines. Click to explore the potential of Kubernetes for Enterprises
What are the benefits of Kubernetes?
The benefits of Kubernetes are highlighted below, showcasing why it is such a powerful tool in the world of cloud computing and containerization:
1. Write Once and Run Anywhere
At this time, the business has to work across a wide range of infrastructure and clouds such as AWS, GCP & Azure, and working across these platforms is made easy using it as its supports a wide range of cloud platforms.
2. Portability and Flexibility
It is compatible with most of the container runtime. Moreover, it can collaborate with virtually underlying architecture, no matter what cloud it is, a public or private cloud or an on-premises server.
It is portable because it can be used on many infrastructures and environments. Most other orchestration tools lack portability because they are attached to specific runtime environments or infrastructures.
3. Multi-Cloud Capability
It partly because of its portability, can host workloads that run on a single cloud and workloads that run across multiple clouds. Furthermore its environment can be easily scaled from one cloud to another.
These characteristics indicate that it suits today's multi-cloud strategies many businesses are pursuing. Other orchestration tools may also work with multi-cloud infrastructures, but it arguably goes above and beyond in terms of multi-cloud flexibility. When considering a multi-cloud strategy, there are additional requirements to consider.
One of the best platforms to deploy and manage containerized applications. Click to explore about our, Helm - Package Manager for Kubernetes
4. Open-Source
It is an entirely open-source, community-driven project managed by CNCF. It has several major corporate sponsors, but no single company "owns" it or has sole control over how the platform evolves. In the CNCF's Project Journey report in 2019, Weaveworks was named one of the top eight contributors.
To many businesses, it's open-source strategy makes it preferable to either closed-source orchestrators (such as those built into public clouds) or open-source but closely associated with only one company.
5. Service Discovery
So, You must be wondering what service discovery is simply put, it's the process of locating a service whenever necessary for completing the tasks within the application. Anyone could make requests either by users or by admins several times. Its service provides protocols for communicating with the pods or a set of pods during their runtime. Pods are the smallest deployable unit of its system, which carries out the essential tasks necessary for the application to function.
In its service, three principal units make the mechanism possible by exposing the service to the system ClusterIP, NodePort & LoadBalancer.
6. Storage Orchestration
Storage is a big problem, and handling it even more. Making the data available always, backing up the data, keeping secret data safe, and many more challenges were there too. Still, as the world is rapidly moving in the digital era, these challenges seem more complex, and we need to solve these. Its architecture provides the necessary aspects that make these challenges.
Easy to handle. The k8s storage architecture is based on volumes. Volumes can be either persistent or maybe non-persistent. K8s provides a requesting mechanism that allows the containers to use storage as per their need, known as volume claims.
7. Automated Rollouts and Rollbacks
In the Digital era, everything is about maintaining consistency in everything from service to quality. Any business demands that they don't want any downtime as it results in huge losses.
Previously updating any application manually was a hectic and lengthy process. If the update has some bugs that may fail, taking back, the updated version was hectic, too, and may result in pausing the service for a certain period. It provides automated rollout and rollback, which is done gracefully without downtime. There are many more advantages, such as Automatic bin packaging, Self-healing, and Secret and configuration management, which simplifies the cloud development environment.
What are the types of Kubernetes Architecture?
Managed Kubernetes Cluster operates in master and worker architecture. In which its master gets all management tasks and dispatch to appropriate Kubernetes worker node based on given constraints.
- Master Node
- Worker Node
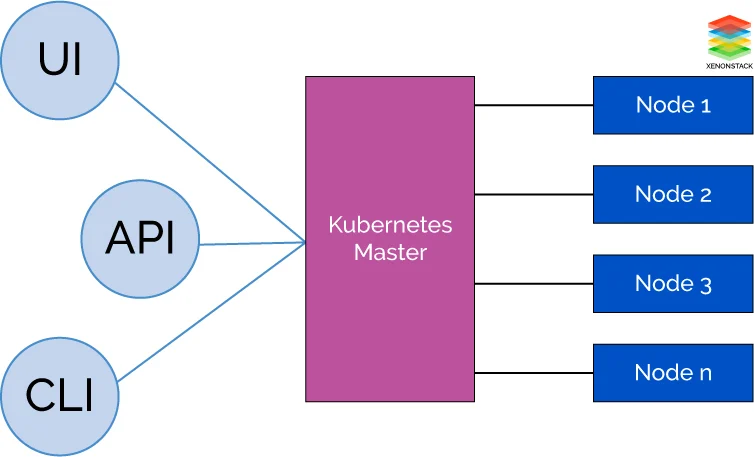
Kubernetes Components
Below we have created two sections so that you can understand better what are the components of its architecture and where we exactly using them.
Master Node Architecture
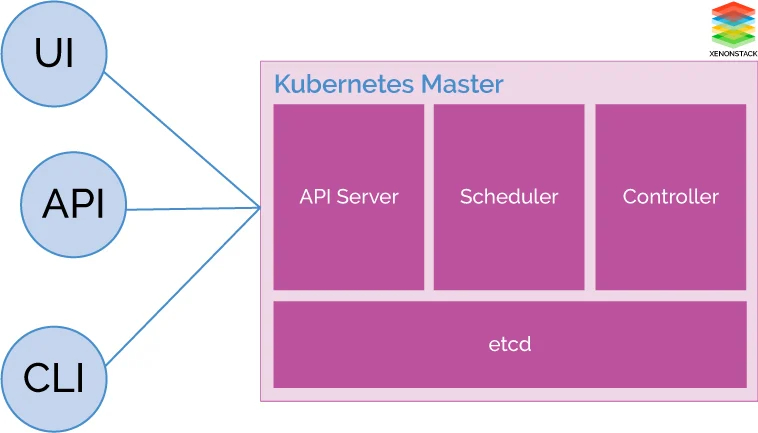
Kube API Server
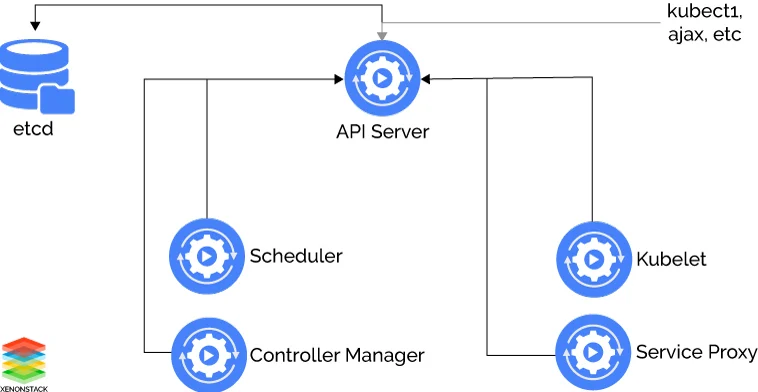
Kubernetes API server is the center of each and every point of contact to its cluster. From authentication, authorization, and other operations to its cluster. API Server store all information in the etc database which is a distributed data store.
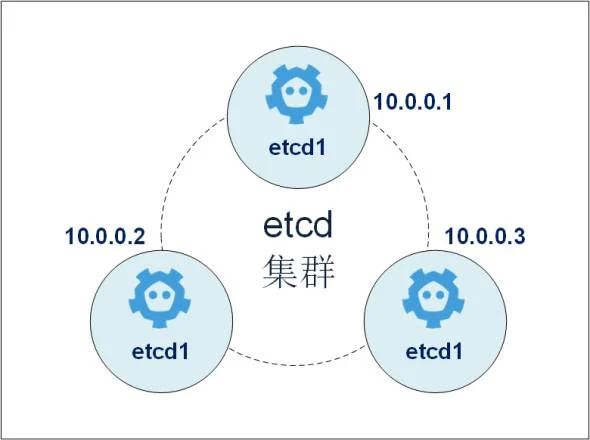
Setting up Etcd Cluster
Etcd is a database that stores data in the form of key-values. It also supports Distributed Architecture and High availability with a strong consistency model. Etcd is developed by CoreOS and written in GoLang. Its components stores all kind of information in etcd like metrics, configurations and other metadata about pods, service, and deployment of the kubernetes cluster.
kube-controller-manager
The kube-controller-manager is a component of Kubernetes Cluster which manages replication and scaling of pods. It always tries to make its system in the desired state by using its API server. There are other controllers also in kubernetes system like
- Replication controller
- Endpoints controller
- Namespace controller
- Service accounts controller
- DaemonSet Controller
- Job Controller
kube-scheduler
The kube-scheduler is another main component of Kubernetes architecture. The Kube Scheduler check availability, performance, and capacity of its worker nodes and make plans for creating/destroying of new pods within the cluster so that cluster remains stable from all aspects like performance, capacity, and availability for new pods. It analyses cluster and reports back to API Server to store all metrics related to cluster resource utilisation, availability, and performance. It also schedules pods to specified nodes according to submitted manifest for the pod.
Worker Node Architecture
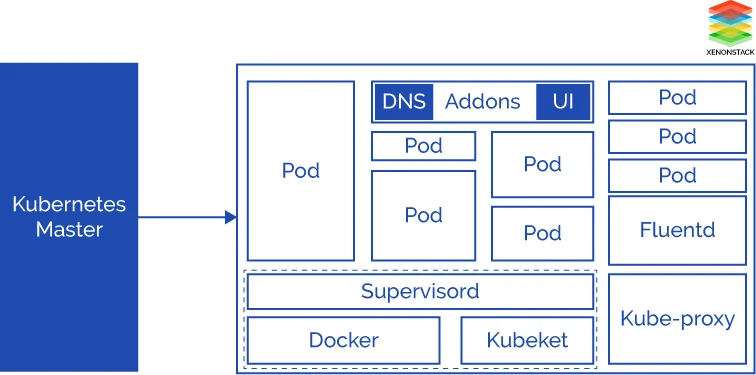
kubelet
The Kubernetes kubelet is a worker node component of its architecture responsible for node level pod management. API server put HTTP requests on kubelet API to executes pods definition from the manifest file on worker nodes and also make sure containers are running and healthy. Kubelet talks directly with container runtimes like docker or RKT.
kube-proxy
The kube-proxy is networking component of the its Architecture. It runs on each and every node of the Kubernetes Cluster.
- It handles DNS entry for service and pods.
- It provides the hostname, IP address to pods.
- It also forwards traffic from Cluster/Service IP address to specified set of pods.
- Alter IPtables on all nodes so that different pods can talk to each other or outside world.
Docker
Docker is an open source container run time developed by docker. To Build, Run, and Share containerized applications. Docker is focused on running a single application in one container and container as an atomic unit of the building block.
- Lightweight
- Open-Source
- Most Popular
rkt, a security-minded, standards-based container engine - CoreOS
rkt is another container runtime for the containerized application. Rocket is developed by CoreOS and have more focus towards security and follow open standards for building Rocket runtime.
- Open-Source
- Pod-native approach
- Pluggable execution environment
Managed Kubernetes Supervisor
Its supervisor is a lightweight process management system that runs kubelet and container engine in running state.
Logging with Fluentd
Fluentd is an open-source data collector for Kubernetes cluster logs.
Spinnaker is a multi-cloud continuous delivery platform that automates the deployment of software changes. It enables organizations to manage application deployments, provides centralized control and visibility through a dashboard, and enforces enterprise policies. Implementing Spinnaker with Kubernetes for Continuous Delivery
What are the basics concepts of Kubernetes?
The below mentioned are the basics kubernetes concepts :
Nodes
Its Nodes are the worker nodes in the cluster. Its worker node can be a virtual machine or bare metal server. Node has all the required services to run any kind of pods. Node is also managed by the master node of the cluster. Following are the few services of Nodes
- Docker
- Kubelet
- Kube-Proxy
- Fluentd
Docker Containers
A container is a standalone, executable package of a piece of software that includes everything like code, run time, libraries, configuration. 1. Supports both Linux and Windows-based apps 2. Independent of the underlying infrastructure. Docker and CoreOS are the main leaders in containers race.
Pods
Pods are the smallest unit of its architecture. It can have more than 1 containers in a single pod. A pod is modelled as a group of Docker containers with shared namespaces and shared volumes. Example:- pod.yml
Kubernetes Deployment
A Deployment is JSON or YAML file in which we declare Pods and Replica Set definitions. We just need to describe the desired state in a Deployment object, and the Deployment controller will change the actual state to the desired state at a controlled rate for you. We can
- Create new resources
- Update existing resources
Example:- deployment.yml
Managed Kubernetes Service YAML/JSON
A Kubernetes Service definition is also defined in YAML or JSON format. It creates a logical set of pods and creates policies for each set of pods that what type of ports and what type of IP address will be assigned. The Service identifies set of target Pods by using Label Selector. Example: - service.yml
Replication Controller
A Replication Controller is a controller who ensures that a specified number of pod “replicas” should be in running state.
- Pods should be running
- Pods should be in desired replica count.
- Manage pods on all worker nodes of the Managed Kubernetes cluster.
Example :- rc.yml
Labels
Labels are key/value pairs. It can be added any kubernetes objects, such as pods, service, deployments. Labels are very simple to use in the configuration file. Below mentioned code snippet of labels Because labels provide meaningful and relevant information to operations as well as developers teams. Labels are very helpful when we want to roll update/restore application in a specific environment only. Labels can work as filter values for its objects. Labels can be attached to kubernetes objects at any time and can also be modified at any time. Non-identifying information should be recorded using annotations.
Container Registry
Container Registry is a private or public online storage that stores all container images and let us distribute them.There are so many container registries in the market.
Microservices Application
Kubernetes is a collection of APIs which interacts with computer, network and storage. There are so many ways to interact with the Managed Kubernetes cluster.
- API
- Dashboard
- CLI
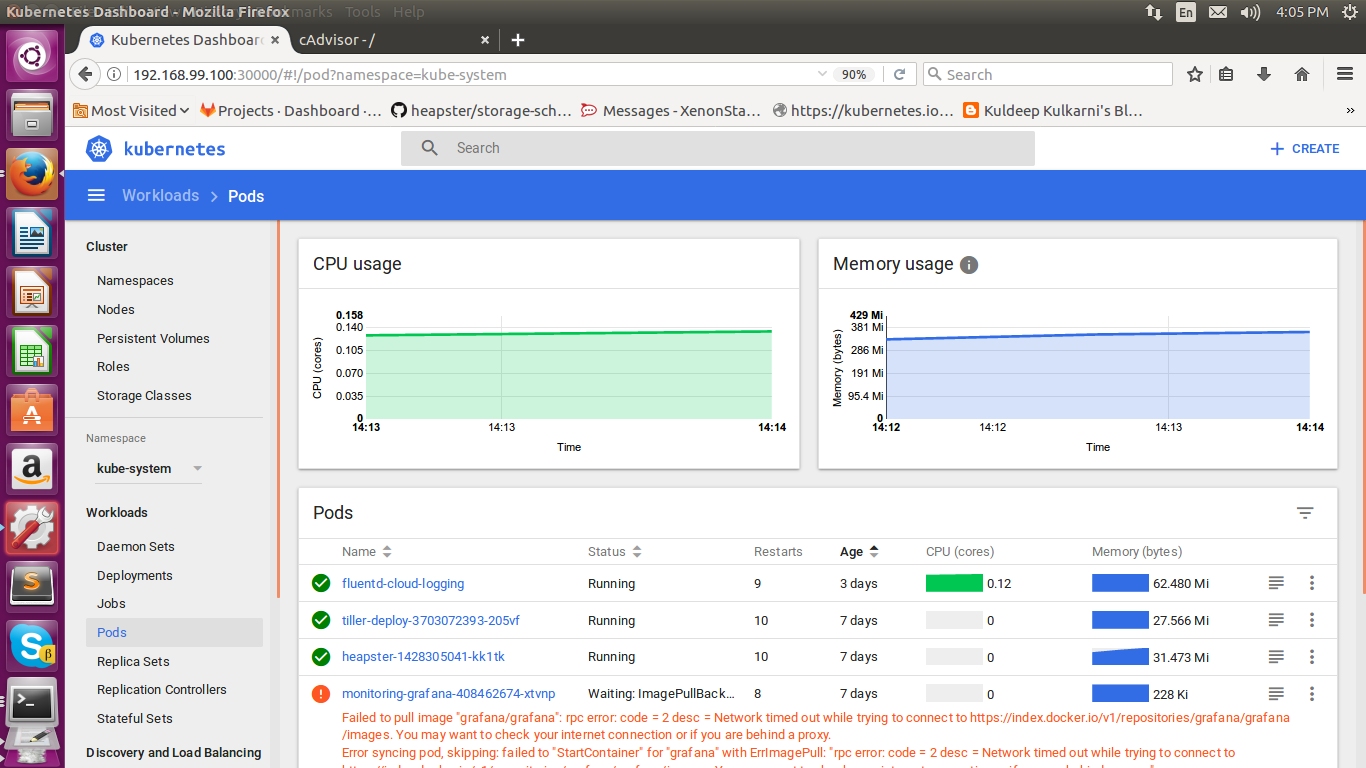
Direct Kubernetes API is available to do all tasks on the cluster from deployment to maintenance of anything inside the cluster. Kubernetes Dashboard is simple and intuitive for daily tasks. We can also manage our cluster from the dashboard.
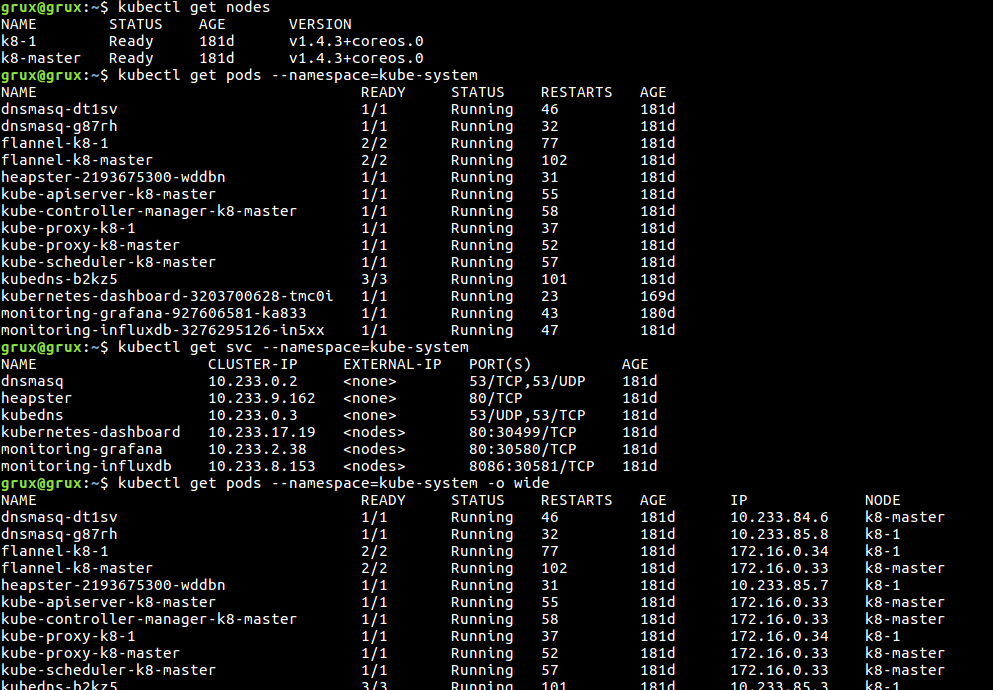
Kubernetes CLI is also known as kubectl. It is written in GoLang. It is the most used tool to interact with either local or remote kubernetes cluster.
Continuous Delivery for Application
Below mentioned deployment guides can be used to most of the popular language application on kubernetes.
- Continuous Delivery for Python Application on Kubernetes
- Continuous Delivery for NodeJS on Kubernetes
- Continuous Delivery for GoLang on Kubernetes
- Continuous Delivery for Java Applciation on Kubernetes
- Continuous Delivery for Scala Application on Kubernetes
- Continuous Delivery for ReactJS on Kubernetes
- Continuous Delivery for Kotlin on Kubernetes
- Continuous Delivery for .Net on Kubernetes
- Continuous Delivery for Ruby on Rails on Kubernetes
What are the best practices of Kubernetes Monitoring?
Kubernetes gives us an easier and managing infrastructure by creating many levels of abstractions such as node, pods, replication controllers, services. Nowadays due to this, we don’t worry about where applications are running or related to its resources to work properly. But in order to ensure good performance, we need to monitor our deployed applications and containers.
There are many tools like Advisor, Grafana available to monitor the kubernetes environment with visualization. Nowadays Grafana is booming in the industry to monitor the environment.
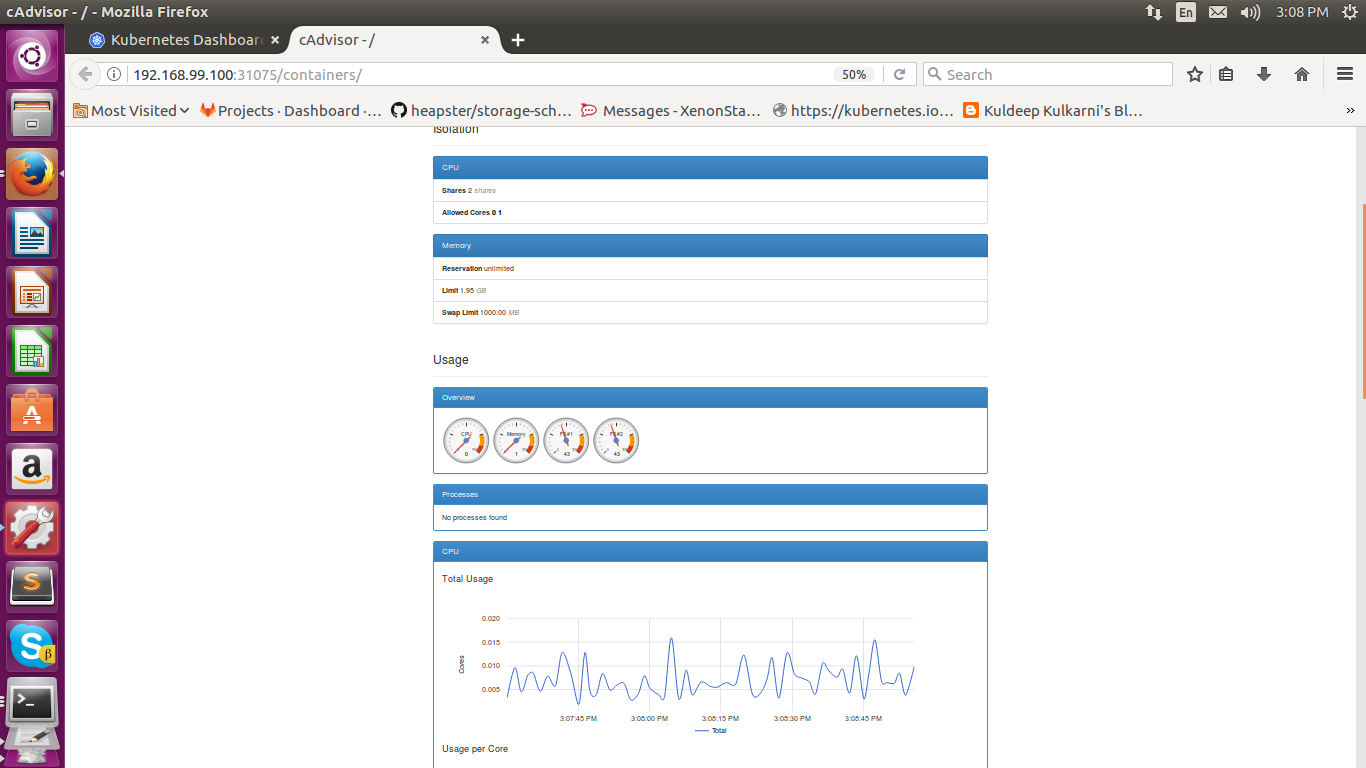
Using cAdvisor to Monitor Kubernetes
cAdvisor is an open source tool to monitor its resource usage and performance. cAdvisor discovers all the deployed containers in the nodes and collects the information like CPU, Memory, Network, file system. cAdvisor provides us with a visualise monitoring web dashboard.
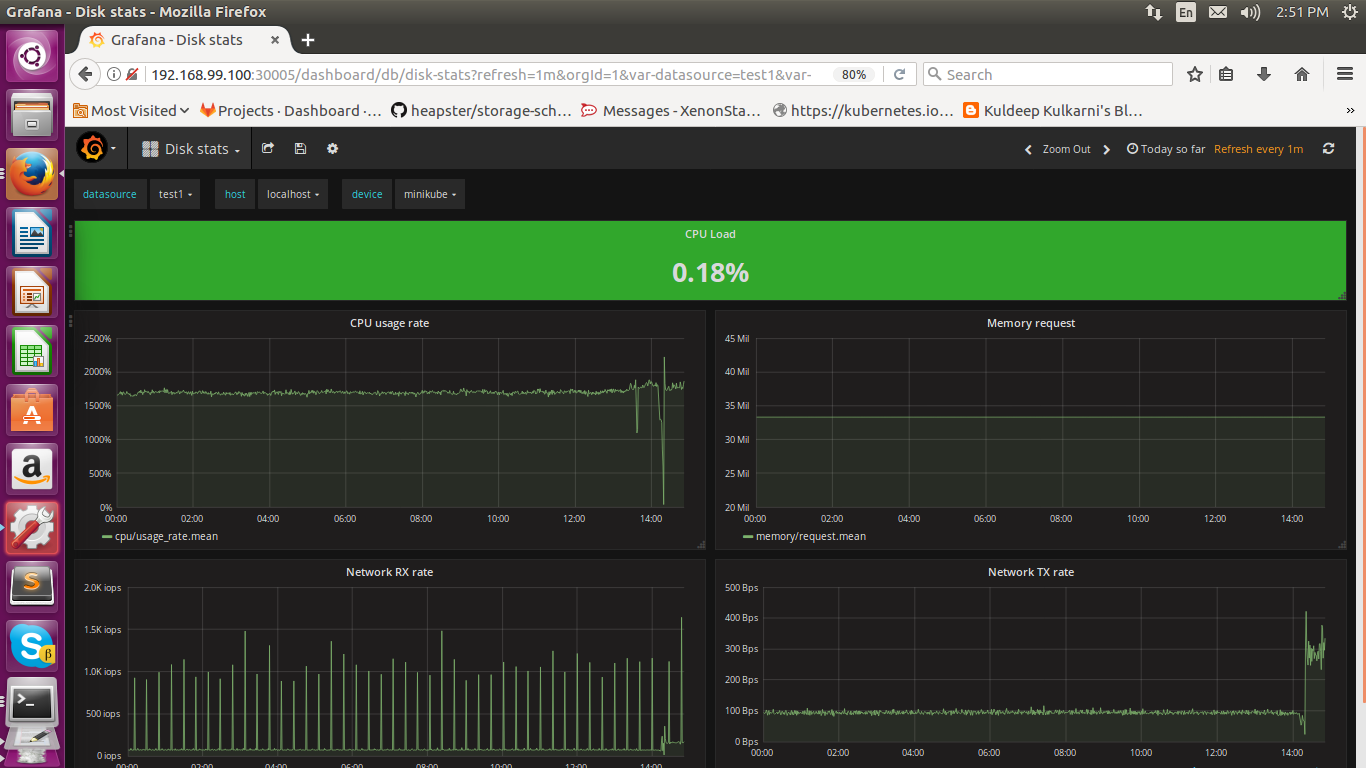
Monitoring Using Grafana
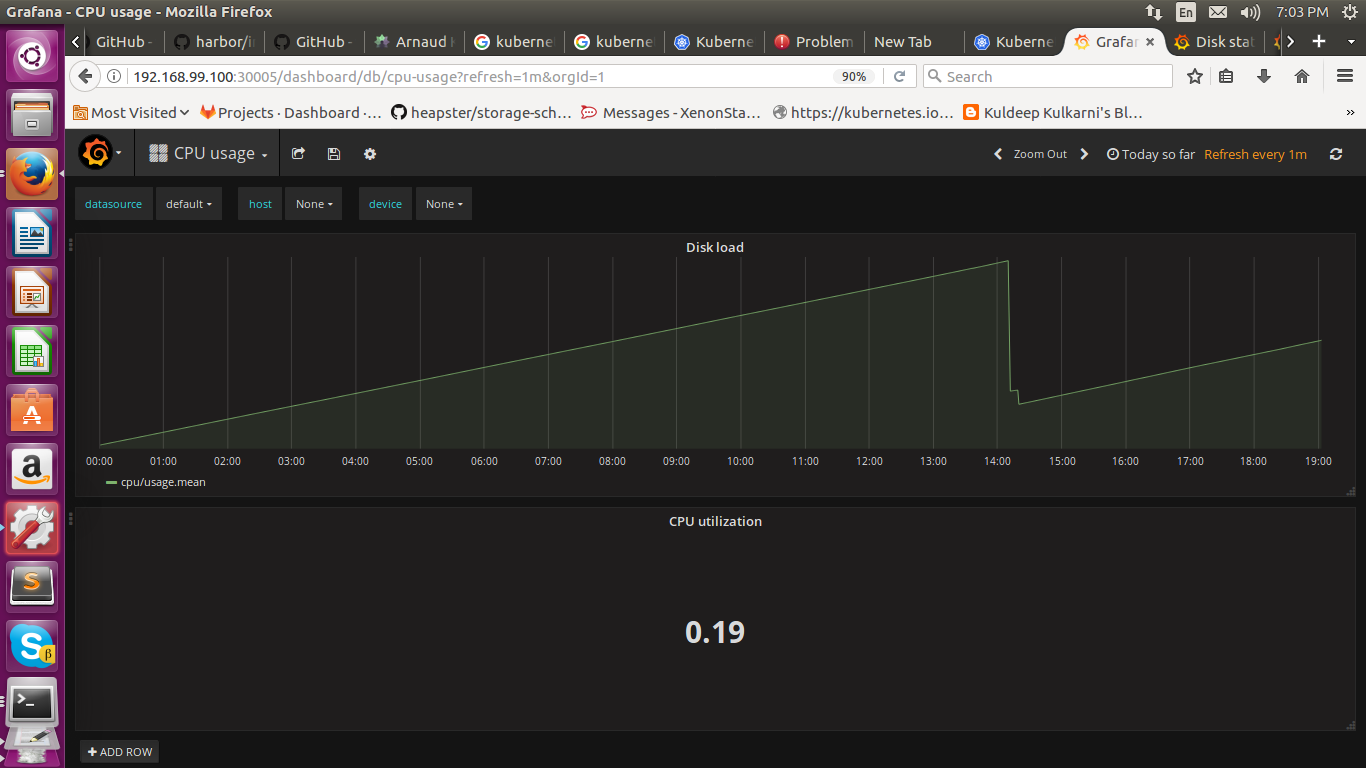
Grafana is an open source metrics analytics and visualization suite. Grafana commonly used for visualizing time series data for application analytics. In Grafana, we need a time series database like “influxdb” and a cluster-wide aggregator of monitoring and event data like heapster. There are 4 steps to get information of kubernetes and visualise it to grafana dashboard.
Step 1: Hepster collects the cluster-wide data from the kubernetes environment.Step 2: After collecting the data hepster provide it to influxdb.
Step3: And now grafana execute the metrics through the influxdb client to collect required data.
Step4: After getting required data grafana visualise the same in graphs. You can create a custom dashboard on Grafana as per your requirement.
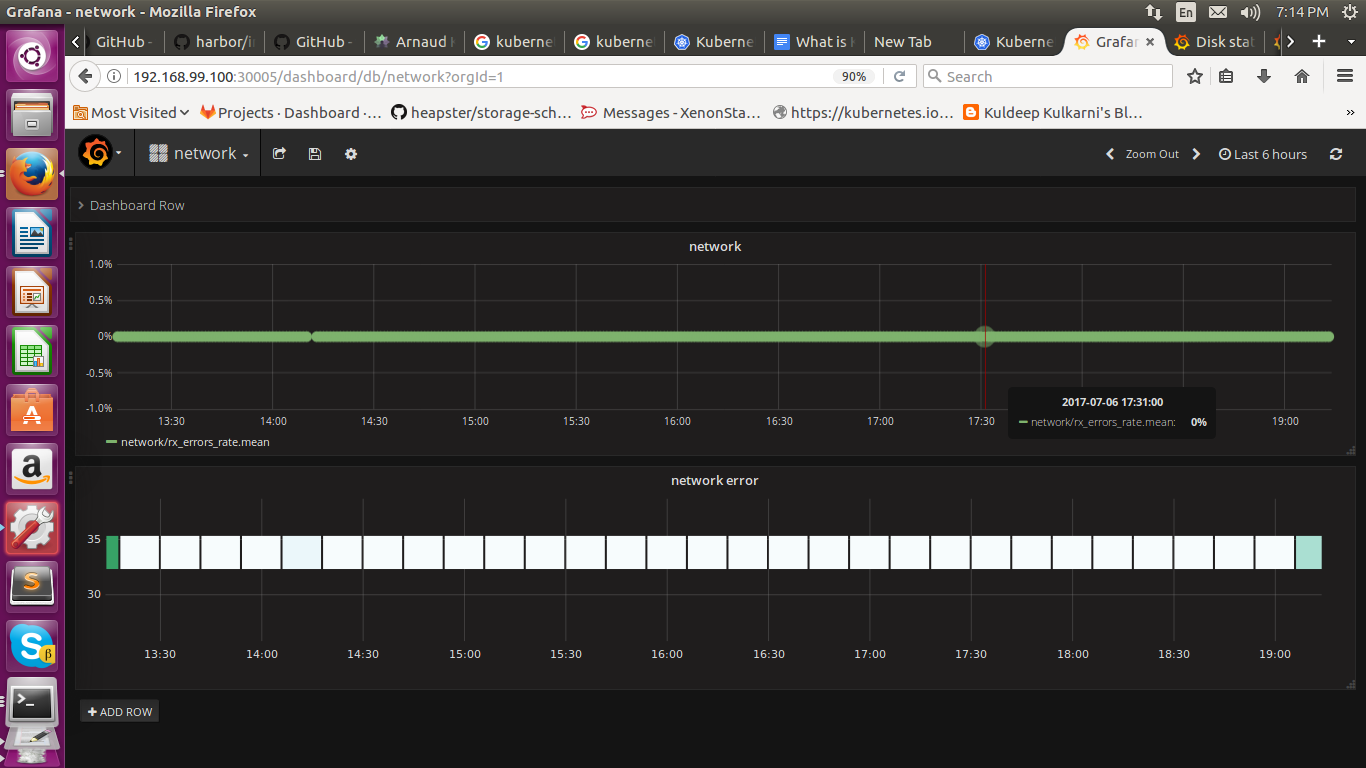
Enterprise Solutions & Production Grade Cluster
The below is the defined Enterprise Solutions & Production Grade Cluster:
Workloads API GA in Kubernetes 1.9
Kubernetes 1.9 introduced General Availability (GA) of the apps/v1 Workloads API, which is now enabled by default. The Apps Workloads API groups the DaemonSet, Deployment, ReplicaSet, and StatefulSet APIs together to form the foundation for long-running stateless and stateful workloads in it. Deployment and ReplicaSet, two of the most commonly used objects in it, are now stabilized after more than a year of real-world use and feedback.
Windows Support (Beta) For Kubernetes 1.9
Kubernetes 1.9 introduces SIG-Windows, Support for running Windows workloads.
Storage Enhancements in Kubernetes 1.9
Kubernetes 1.9 introduces an alpha implementation of the Container Storage Interface (CSI), which will make installing new volume plugins as easy as deploying a pod, and enable third-party storage providers to develop their solutions without the need to add to the core codebase.

Kubernetes Approach: Simplifying the Containers Management
Kubernetes is an open-source container for managing full stack operations and containers. Discover how XenonStack's Managed Kubernetes Consulting Solutions For Enterprises and Startups can help them for Migrating to Cloud-Native Application Architectures means re-platforming, re-hosting, recoding, rearchitecting, re-engineering, interoperability, of the legacy Software application for current business needs. Application Modernization services enable the migration of monolithic applications to new Microservices architecture. Deploy, Manager and Monitor your Big Data Stack Infrastructure on it. Run large scale multi-tenant Hadoop Clusters and Spark Jobs on it with proper Resource utilization and Security. Please review the below steps:
- Explore more about Kafka Security with Kerberos on Kubernetes
- Discover how to Deploy Cloud Native Application on Kubernetes
- BlockChain App Deployment with Microservices on Kubernetes


