Why Continuous Integration and Deployment?
Like in Modern Web Applications, it needs Agile systems because of the ever-changing requirements of the clients and consumers. In Machine Learning the challenge is to make the system that works well with the real world, and the real-world scenarios change continuously. The system needs continuous learning and training from the real world. The solution is DevOps for Machine learning and deep learning. Which continuously trains the model on the new data after some time and then validates and tests the model accuracy to make sure it will work well with the current real-world scenarios.A process in which, Modern software engineering Culture and Practices to develop software. Click to explore about, What is DevOps and it's Processes?
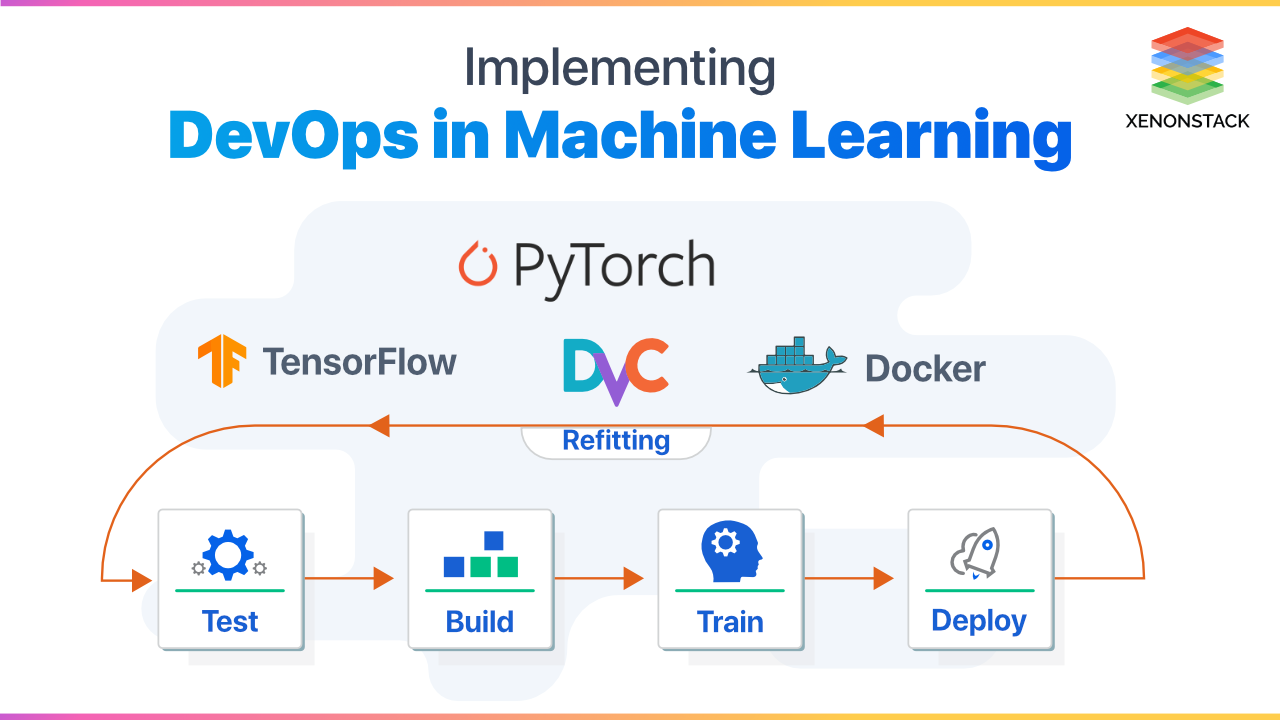
DevOps for ML, Tensor Flow and PyTorch
TensorFlow and PyTorch are open source tools that help for DevOps for machine learning. Google develops TensorFlow and based on Theano Whereas PyTorch is developed by Facebook and based on Torch. Both frameworks define computational graphs. In TensorFlow, it needs to determine the entire computational graph and then run the ML algorithms. PyTorch uses dynamic graphs and creates it on the go.
TensorFlow has Tensorboard for visualization and enables directly on the browser. PyTorch doesn’t have a tool like that, but Matplotlib can be used with it. TensorFlow has more community support and online solutions than PyTorch.Whichever framework is used to build the Machine Learning Model, the CI/CD is a much-needed thing. Developers or Data Scientists spend most of their time in managing and Deploying their model to production manually, and this makes a lot of human errors. This needs to be an automated process with a well-defined pipeline and Model Versioning. The skills needed by a data scientist is changing now, its less visualization and statistics-based and moving closer to engineering. Continuous Integration and Deployment of Machine Learning Models is the real challenge in the Data Science world, Productionizing the models requires proper Integration and Deployment pipeline.
As the real world changes continuously so the system should have the capability to learn with time. Continuous Integration and Deployment Pipeline make this happen. Currently, if a modern application needed to be developed a continuous pipeline then tools like Git, Bitbucket, GitCI, Jenkins were used for versioning and management of the code. As in the case of Modern application, only the codebase is required to be managed and versioned but in Machine Learning and AI Applications things are more iterative and complex. The data is another thing to accomplish here. A system is required which can version and manage the data, models and intermediate data.
The debate about Continuous Integration vs Continuous Deployment has recently been the town's talk. Click to explore about, Continuous Integration vs Continuous Deployment
What is the Continuous Development life cycle?
Git is a source code management and also a version control management tool. Versioning the code is much more critical for product releases, and there is history for every file for exploring the changes and reviewing the code.Git for versioning and managing code
In Machine learning and AI systems, the model code needs to manage for releases and changes tracking. Git is the most used source code management tool used. In Continuous Integration and Continuous Deployment, Git manages the versions by tagging branches, and git-flow can be used for feature branches.Dvc for versioning models and data
Unlike source code, the size of the model and data is much larger, and Git is not suitable for this kind of cases where the data is, and models files are large. Dvc is a Data science version control system that provides the end to end support for managing the Training data, intermediate data and model data.Version control
DVC provides the commands like Git to add commit and push models and data to S3, Azure, GCP, Minio, SSH. It also includes data provenance for tracking the evolution of Machine Learning Models. Dvc helps in reproducibility if need to get back to a particular experiment.Experiment management
Metric tracking is easy to use using DVC. It provides a Metric tracking feature that lists all the branches along with metrics values and picks the best version of the experiment.Deployment and Collaboration
Dvc push-pull command is available to push the changes to production or staging. It also has a built-in way to create DAG using ML steps. DVC run command is used to create the deployment pipeline. It streamlines the work into a single, reproducible environment and also makes it easy to share the environment.Packaging Models
There are a vast number of ways with models that can be packaged but the most convenient and automated using Docker on Kubernetes. Docker is not only applied to packaging but also as a development environment. It also handles version dependency management. It provides more reliability than running Flask on a Virtual Machine. In this approach, Nginx, Gunicorn and Docker Compose will be used to create a scalable, repeatable template for making it easy to run with continuous integration and deployment.Directory Structure
├── README.md
├── nginx/
├ ├── Dockerfile
├ └── nginx.conf
├── api/
├ ├── Dockerfile
├ ├── app.py
├ ├── __init__.py
├ └── models/
├── docker-compose.yml
└── run_docker.sh
How to perform Continuous Model Testing for PyTorch and TensorFlow?
Feature Test of Continuous Model Testing are below:
- value of features lies between the threshold values
- feature importance changed concerning previous
- Feature a relationship with the outcome variable in terms of correlation coefficients.
- Feature unsuitability by testing RAM usage, inference latency, etc.
- generated feature violates the data compliance related issues
- code coverage of the code generating functions
- static code analysis outcome of code generating features
Accuracy Test
Test the accuracy using unseen data on the model and check if the resultant efficiency meets the threshold or not. It is an essential step of testing in Machine Learning systems that helps to identify if a model needs to retrain on more data.
Continuously Retrain and Manage Models Workflow
The model needs to retrain on new data as the data distribution can be expected to drift over time. So it should be a continuous process. This means that the predictions on static ML models become less accurate with time.
Model workflow management with Airflow
To build a complex pipelines and workflow management airflow is used as the monitoring of trained models and scheduling and DAG need to implement. Airflow handles all tasks in one place.
- Schedule dependent jobs
- Give the visibility into successes and failures and the overall ML pipeline
- Define feature extraction and training multiple models parallel in the pipeline
Docker files being pushed to ECS and a Training service pulls the training data and starts training on Kubernetes using build image. Multiple pods can be run parallelly for numerous models.

Continuous Deployment of ML services
Newly trained models are saved to S3, and when the newly trained model is available on AWS S3, a Continuous Deployment listener update the model and deploy the latest trained model on Kubernetes.A Comprehensive Approach
The CI/CD of ML models is essential and will provide more productivity in building AI systems by following best practices and methods. Tools are changing and enhancing faster than ever to make CI/CD more streamlined so that the Data scientists can focus on solving the business problems and make effective real-time accurate Machine learning models. To learn more about Continuous Integration and Deployment we advise taking the following steps -- Learn More About Continuous Delivery Best Practices
- Get an Insight About Continuous Delivery of Machine Learning Pipeline


