
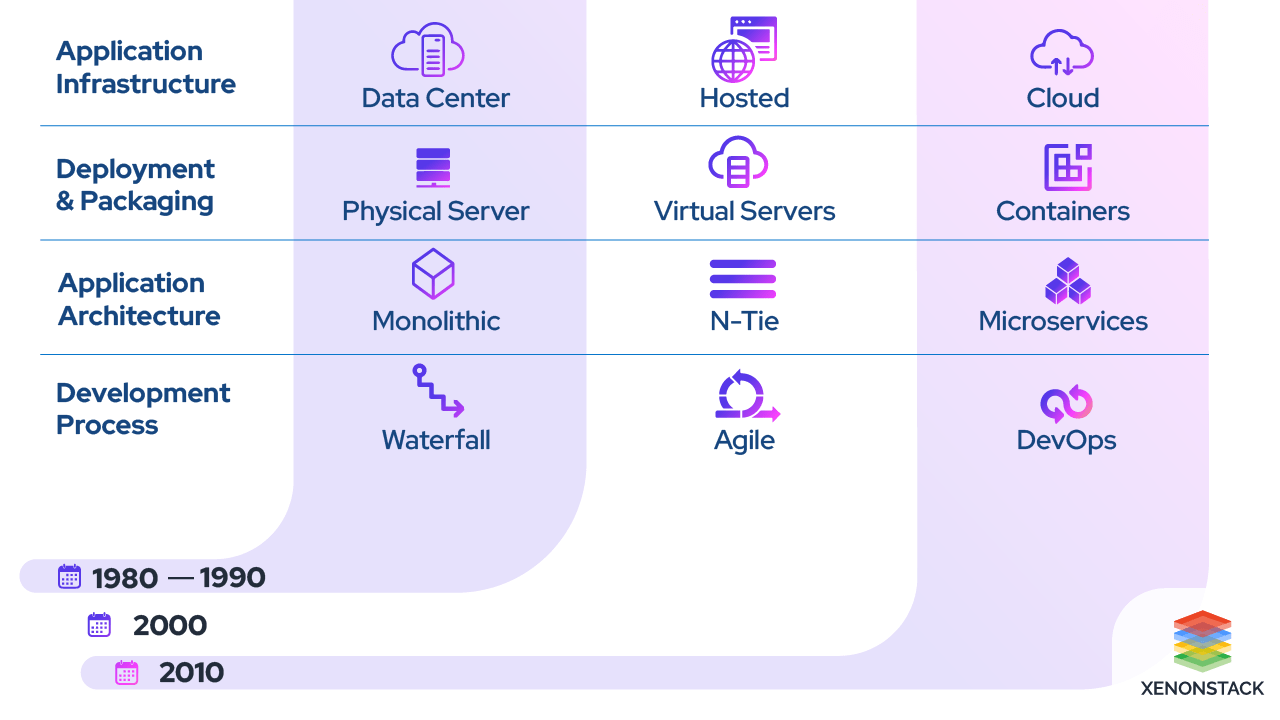
What is Cloud Native?
Cloud-native is an approach to developing, building, and shipping applications using modern Cloud computing. These applications natively utilize services and infrastructure provided by Cloud computing providers, such as Amazon Web Services (AWS) or Google Cloud Platform (GCP). Various servers and databases are distributed across many regions.
It is mainly built as Microservices, a modern software architecture. Public and Private Clouds are used for modern Cloud Native technologies. The best part is that developers get unlimited computing power, on-demand computing resources, application frameworks, and services for developers building it. It helps in quickly turning new ideas and solutions to the market. Learn more about the Three Rs of Security in this insight.
These are loosely coupled, dynamically deployed, and managed using various services on the Cloud. They are independent of underlying hardware and software, making them portable. Modern practices are used to build Cloud Native technologies, such as DevOps, Agile methodology, Cloud platforms (AWS, GCP, Azure), Microservices, Containers (like Docker, Kubernetes), and CI/CD pipelines.
What are the Features of a Cloud Native?
-
Microservices-Based: Microservices can be viewed as a set of independent services, or modules, that make up an application. As a result, each service refers to its data and is designed to support a particular business objective. Generally, these modules use Application program interfaces to communicate and exchange data.
-
API Based: Besides providing simplicity and security, APIs are also used to connect microservices and containers, allowing for easier maintenance and management.API enables the microservices, which are co-located between loosely coupled services with the integration and acting as a glue that keeps them connected.
Why is Cloud Native Important?
Following are the reasons why Cloud Native technologies development matters
1. It Provides Microservices Architecture
Microservices architecture has tremendous benefits, such as loosely coupled services, scale-out, faster release cycles, and lower complexity as it's divided across many teams.
2. Provides all Advantages of a Cloud
It helps in delivering applications at a faster rate, as per customer needs. Cloud provides all the flexibility and resilience of these modern applications.
3. All Communication is API-Based, Which is Quick and Transparent
Services communicate via lightweight APIs, which help reduce the complexity and extra overhead of deploying scaling applications. All communication happens via service interface calls over the network. There is no risk of directly linking services and shared memory models used in Monolith.
What Advantages does a Cloud-Native Approach offer to Businesses?
The cloud-native approach offers several advantages to businesses, making it a game-changer in today's digital landscape. By adopting a cloud-native approach, businesses can boost their efficiency, cut costs, and ensure the uninterrupted availability of their applications.
1. Boost Efficiency
Cloud-native development revolutionizes application development efficiency by adopting agile practices such as DevOps and continuous delivery (CD). Developers can rapidly build scalable applications by leveraging automated tools, cloud services, and a modern design culture.
2. Cut Costs
Embracing the cloud-native approach eliminates the need for companies to invest in expensive physical infrastructure procurement and maintenance. This leads to significant long-term savings in operational expenditure. Furthermore, the cost savings gained from building cloud-native solutions can also benefit clients.
3. Ensure Uninterrupted Availability
Cloud-native technology empowers companies to create resilient and highly available applications. Feature updates no longer cause downtime, and companies can effortlessly scale app resources during peak seasons, ensuring a seamless and positive customer experience.
Cloud-Native Architecture
Cloud-native architecture is a powerful combination of software components that empowers development teams to build and operate highly scalable applications in the cloud. According to the CNCF, this architecture relies on key technological building blocks such as immutable infrastructure, microservices, declarative APIs, containers, and service meshes. These components work together seamlessly to create a robust and efficient cloud-native ecosystem.
 Immutable Infrastructure
Immutable Infrastructure
Immutable infrastructure is a foundational concept in cloud-native architecture. It refers to the practice of deploying servers for hosting cloud-native applications and leaving them unchanged after deployment. Unlike traditional infrastructure, where manual upgrades are required, immutable infrastructure takes a different approach. If the application needs more computing resources, the old server is discarded, and the application is seamlessly moved to a new high-performance server. This eliminates manual intervention and makes the entire deployment process in the cloud-native environment more predictable and efficient.
Microservices
Microservices are small and autonomous software components that create a comprehensive cloud-native application. Each microservice is designed to address a specific problem, allowing developers to change the application by focusing on individual microservices. This loose coupling ensures the application remains functional even if one microservice encounters an issue.
API
APIs, or Application Programming Interfaces, play a vital role in cloud-native systems by facilitating the seamless integration of loosely coupled microservices. Unlike traditional approaches that specify step-by-step instructions, APIs provide a clear understanding of the data that a microservice requires and the results it can deliver. This allows for a more efficient and flexible exchange of information, ultimately enhancing the overall functionality and performance of cloud-native applications.
Service Mesh
The service mesh is a crucial software layer within the cloud infrastructure, effectively managing communication between various microservices. Developers leverage the service mesh to seamlessly incorporate additional functionalities into the application without writing new code.
Containers
Containers are the building blocks of cloud-native applications, acting as the smallest computation unit. They encapsulate the microservice code and necessary files, enabling cloud-native applications to operate independently of the underlying operating system and hardware. This flexibility allows software developers to deploy these applications seamlessly on various platforms, including on-premises, cloud infrastructure, or hybrid clouds. Utilizing containers, developers package the microservices along with their dependencies, such as resource files, libraries, and scripts, essential for the smooth execution of the main application.
Benefits of containers
Containers offer many advantages, including efficient resource utilization, instant deployment, and seamless scalability to meet your application's demands.
-
You use fewer computing resources than conventional application deployment
-
You can deploy them almost instantly
-
You can scale the cloud computing resources your application requires more efficiently.

What are the Best Practices of Cloud Native?
Here are some best practices for Cloud Native:
-
Automatic Provisioning: Streamline the process of setting up different environments by using code stored in GIT. This ensures a consistent and efficient deployment.
-
Automatic Redundancy: Cloud Native applications are designed to be highly resilient. When an issue arises, these apps seamlessly and automatically switch to another server or VM, ensuring uninterrupted service.
-
Automatic Scaling: Cloud Native applications are built using Microservices, allowing for effortless resource scaling based on traffic spikes. This ensures optimal performance and cost-effectiveness.
-
API Exposure: Expose your application's API using REST or grpc, enabling seamless integration with other systems and fostering collaboration.
-
Testing Enablement: Prioritize comprehensive testing to ensure the reliability and functionality of your Cloud Native applications.
-
Firewall and Service Mesh: Implement robust firewall protection and service mesh technologies to enhance the security and manageability of your applications.
-
Multi-Cloud Deployment: Leverage the flexibility and scalability of multiple cloud providers to achieve redundancy, performance optimization, and cost efficiency.
-
Continuous Integration/Continuous Delivery (CI/CD): Set up automated CI/CD pipelines to streamline the software development process, ensuring faster time-to-market and improved agility.
What is the CNCF?
The Cloud Native Computing Foundation (CNCF) was founded in 2015 as an open-source foundation that guides organizations on their cloud-native journey. With a focus on supporting the development of essential cloud-native components, including popular technologies like Kubernetes, the CNCF has become a valuable resource for the open-source community. Notably, XenonStack is among the prestigious members of the CNCF, highlighting its commitment to advancing cloud-native computing.

Best Cloud Native Tools
-
Fluentd - The Fluentd tool is used for logging and is responsible for collecting and sharing log data. It seamlessly sends the log data to log aggregation tools such as AWS CloudWatch.
-
Prometheus - Prometheus is a powerful monitoring tool that records Time-Series data for distributed microservices. It provides valuable insights and helps ensure the smooth functioning of your applications.
-
Kubernetes - As a container orchestration system, Kubernetes allows you to deploy and manage containers efficiently. It simplifies the management of your application's infrastructure, making it easier to scale and maintain.
-
ELK Stack - The ELK Stack is a comprehensive monitoring solution that combines Elasticsearch, Logstash, and Kibana. It enables you to monitor and analyze logs effectively, providing valuable insights into your application's performance.
-
Grafana - Grafana is a highly versatile visualization tool that allows you to create interactive and visually appealing dashboards. Grafana allows you to easily monitor and analyze your application's metrics and performance data.
-
AWS, Google Cloud - These cloud computing services provide a reliable and scalable infrastructure for hosting your cloud-native applications. They offer various services and features to support your application's needs.
-
Istio - Istio is a powerful tool that enables the implementation of a service mesh. It provides advanced features for traffic management, security, and observability, ensuring seamless communication between microservices.
Compressive Approach to Cloud Native
Building and managing native cloud applications is fascinating to many enterprises, who want to deliver flawless customer experience and speed up the execution of their operations. Kindly take the below steps before you proceed further with this.
- Get an insight into Cloud Native Databases on Docker and Kubernetes
- Explore the Cloud Native Architecture Patterns and Design
- Discover the Challenges of Deploying Cloud Native DevOps on Kubernetes



