
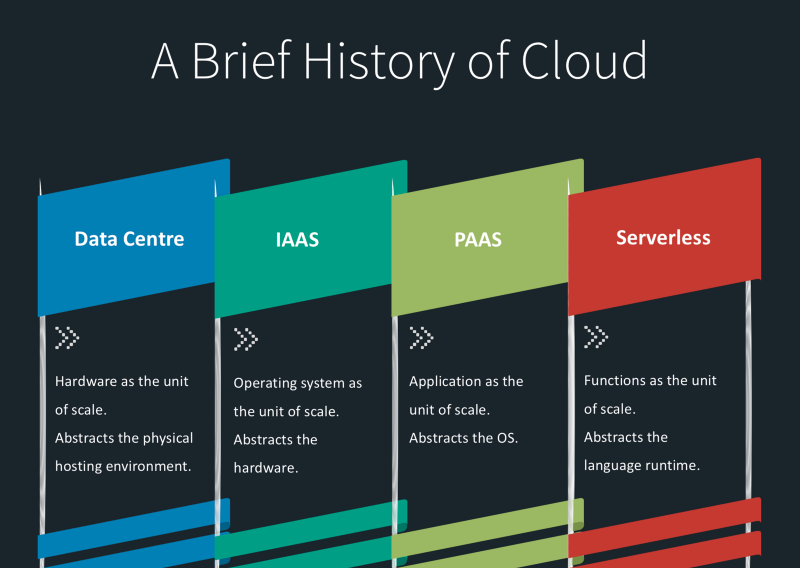
Introduction to Serverless Microservices Architecture
The phrase “serverless” doesn’t mean servers are no longer required. It solely proposes that developers no longer have to think that much about them. Going serverless lets, developers shift their focus from the server level to the task level, writing codes.What does it mean to have servers?
First, let’s talk about what it means to have servers (virtual servers) providing the computing power required by your application. Owning servers comes with responsibilities -- Managing the primitives (functions in applications or objects when it comes to storage) map to server primitives (CPU, memory, disk, etc.).
- Own provisioning (and therefore paying) for the capacity to handle your application’s projected traffic, independent of whether there’s actual traffic or not.
- Own managing reliability and availability constructs like redundancy, failover, retries, etc.
Serverless computing can also be recognized as FaaS (Function-as-a-Service) architecture of cloud computing. Click to explore about, Serverless Computing Applications and Architectures
What are the benefits of Microservices Architecture?
Microservices Architectures have lots of genuine and significant benefits:
- Systems built in this way are inherently loosely coupled.
- The services themselves are very simple, focusing on doing one thing well.
- Multiple developers and teams can deliver independently under this model.
- They are a great enabler for continuous delivery, allowing frequent releases whilst keeping the rest of the system available and stable.
What are the Advantages of Serverless Architecture?
Why should one move to serverless architecture can be adequately described through its benefits:- PaaS and Serverless -A user of traditional PaaS has to specify the number of resources - such as dynos for Heroku or gears for OpenShift - for the application. The Serverless platform will find a server where the code is to run and scale up when necessary.
- Lower operational and development costs -The containers used to run these functions are decommissioned as soon as the execution ends. And the execution is metered in units of 100 ms, You don't pay anything when your code isn't running.
- It fits with microservices to implement as functions- Serverless architectures refer to applications that significantly depend on third-party services (known as Backend as a Service or "BaaS") or on custom code that's run in ephemeral containers (Function as a Service or "FaaS"). But there are cons related to moving your application to FaaS, which is discussed in our next post Building Serverless Microservices with Python.
How to Migrate to a Serverless Microservices Architecture in Java?
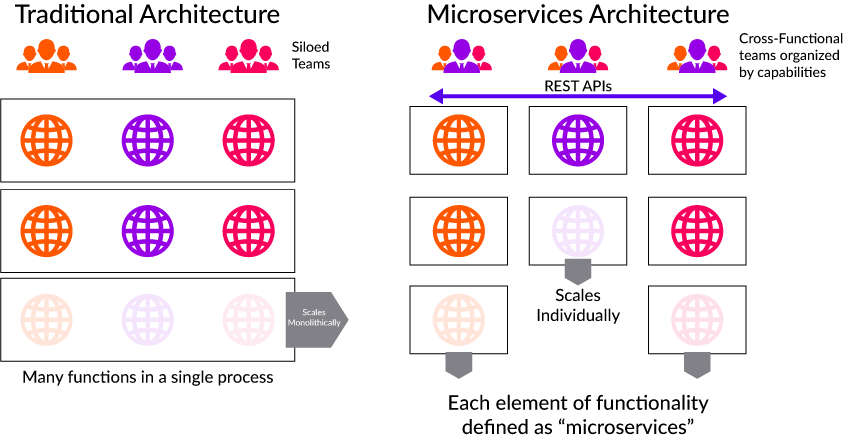
In a simple definition, Serverless Microservices Architecture is independently scalable, independently deployable systems that communicate over some protocols HTTP (XML, JSON), Thrift, Protocol Buffers, etc. Microservices are the Single Responsibility Principle at the codebase level. Below are some of the factors to follow for building Microservices:- One code per app/service: There is always a one-to-one correlation between the codebase and the service.
- Explicitly declare and isolate dependencies: This can be possible by using packaging systems.
- Use environment variables to store configurations.
- Strictly separate build, release, and run stages.
- Treat logs as event streams. Route log event stream to analysis system such as Splunk for log analysis.
- Keep development, staging, and production as similar as possible.
 This post will implement a function that integrates with a database (MongoDB used here). We are going to implement this new function in Java using Spring Framework. So, Let’s start -
This post will implement a function that integrates with a database (MongoDB used here). We are going to implement this new function in Java using Spring Framework. So, Let’s start -
Employee Service
We will build an Employee Service consisting of a function to show Employees information from the database. For Demo purposes, we are here implementing one function, “GetEmployee.”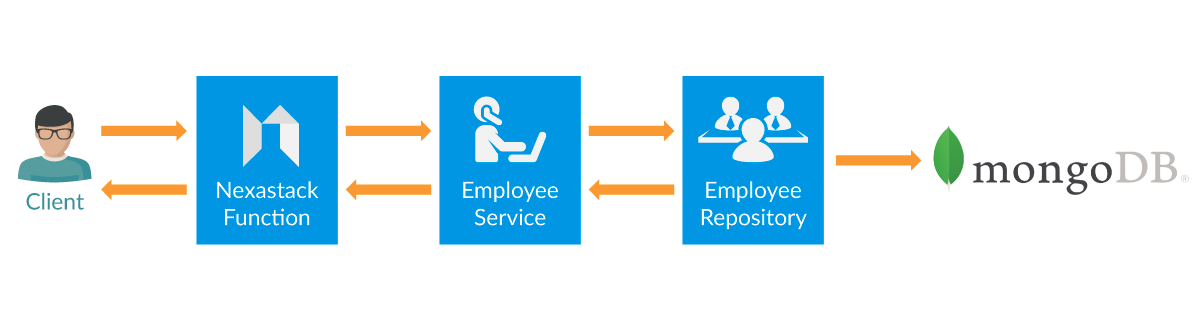
Setting up MongoDB Instance
- Install MongoDB and configure it to start.
- Create Database EmployeeDB
- Create table Employee
- Insert some records into the table for the demo.
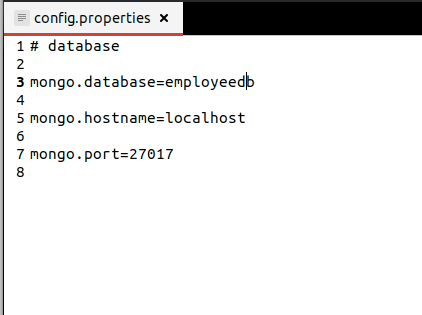
- Write a file “config.properties” to set up configuration on the serverless architecture.
Create Spring Microservice
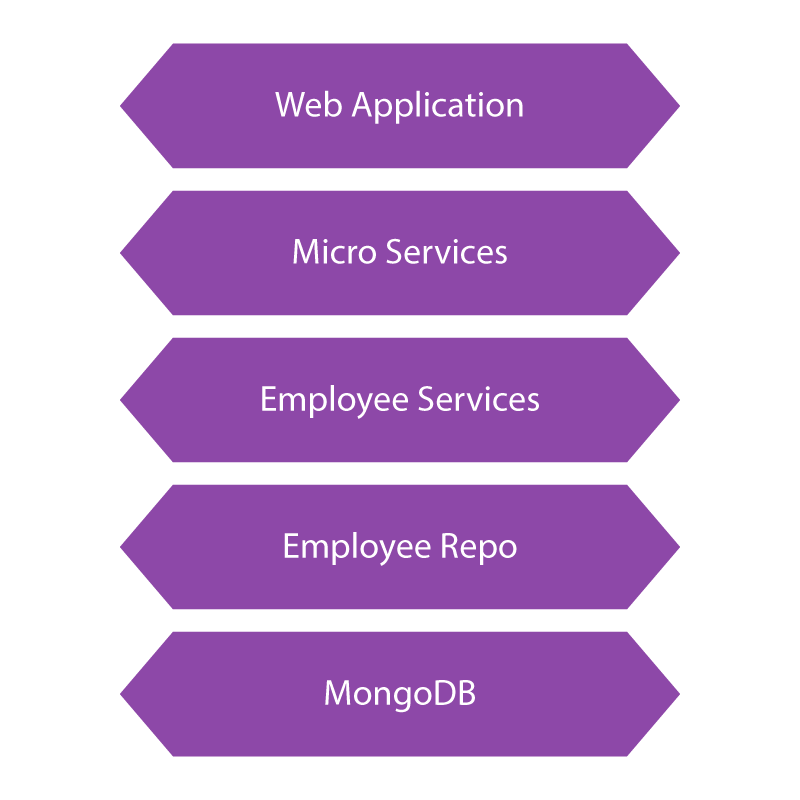
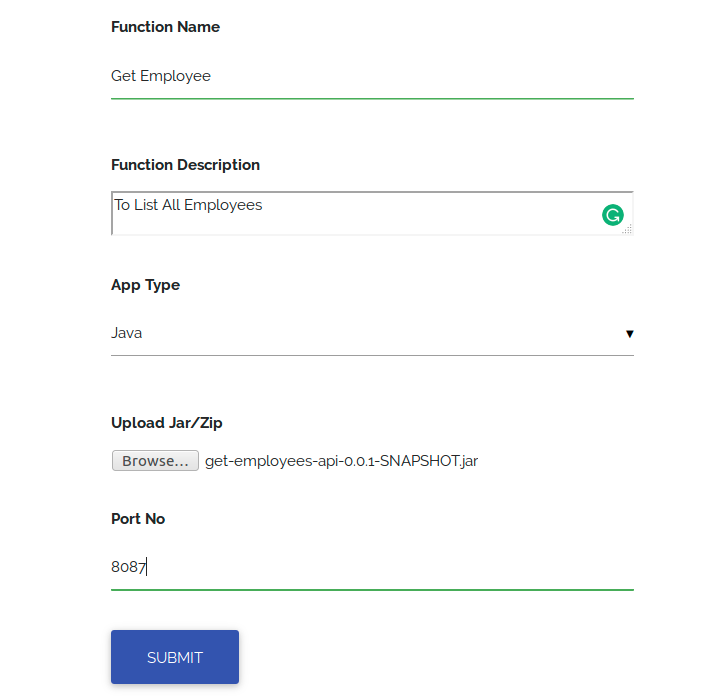
Create Deployment Package
To create a function, first create a function deployment package, a JAR file consisting of your code and any dependencies. We have to build a JAR file named “get-employees-api-0.0.1-SNAPSHOT.jar” containing java code to show employees.
- Create a directory, for example, project-dir.
- Save all of your Java source files at the root level of this directory. The folder named “app” serves this objective in the demo.
- Add any of the extra libraries used in a folder “lib.”
- Zip the content of the project-dir directory, which is your deployment package.

Setup Microservices on NexaStack
- Fill in the entries and upload your function.
- Must fill the port number field with a port number on which you want your service to run.
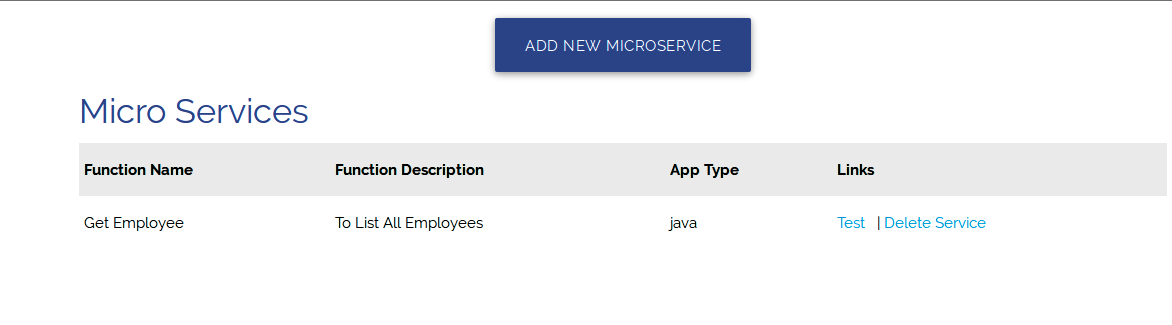
Testing
- Once finished with uploading the function, the Service is active to test
- Click on "Test,," and your service is up in few seconds on the port number specified in the previous step.
Serverless Computing: The Future of Cloud
The above shown is just a demo of Serverless computing, and there is a lot to add to the field. Improved ability to respond to a software event (the shopper's click), retrieve the analyst's code, and quickly run it might prove instrumental in converting your shoppers into buyers. As said, "Software is eating the world. Companies that can develop software most effectively will be among those that succeed" at thriving in such a world.

There would be no long pause, no shifting to another application, no launch of a virtual server in the cloud. There would be dozens or hundreds of microservices for a company using them, sitting in the public cloud until demanded, then running in an expedient burst to produce results. You can also explore more about Java Microservices Application Deployment on Kubernetes in this blog. Till then, explore how going serverless can help your business attain new heights and Contact Us for the best possible solution.
- Read more about Laravel Docker Application Development
- Learn more about the Best Practices for Monitoring Docker Container
- Get in Touch with us for Container Security Solutions and Strategy


