
Introduction to Amazon SageMaker
When it comes to Machine Learning (ML) and giving it as a service, it requires Data Engineering, ML, and DevOps expertise. While deploying a production model, several issues arise, like versioning issues and problems in the model pipeline. Solving these issues is time-consuming. ML Research Scientists and practitioners at Amazon came out with a solution to run the entire pipeline of machine learning powered by AWS called Amazon Sagemaker. With the availability of tools for every stage, various in-house tools are available to ease the model building and deployment. AWS SageMaker uses Jupyter Notebook and Python with Boto to connect with the s3 bucket, or it has its high-level Python API for model building. The compatibility with modern deep learning libraries like TensorFlow, PyTorch, and MXNet reduces the model building time.Many different approaches are possible when using ML to recognize patterns in data. Source –Machine learning workflow
What is a Machine Learning Pipeline?
A Machine Learning Pipeline is an executable workflow of the machine learning task. It helps to optimize, build, and manage ML workflows. Listed below are the features of the ML pipeline:
- Fetch data - Get real-time data from Kafka streams or repository hosting data. SageMaker requires the data to be in an AWS s3 bucket for setting up the training job.
- Data Pre-processing - This step involves data wrangling and data preparation for training. Data wrangling is one of the most time-consuming steps in a machine learning project. Amazon SageMaker Processing enables the running jobs to pre-process data for training and post-process for generating inference, feature engineering, and model evaluation at scale.
- Model Training - The pre-processing pipeline is for both training and testing data. Amazon SageMaker has popular algorithms already built into it. Import the library and use it.
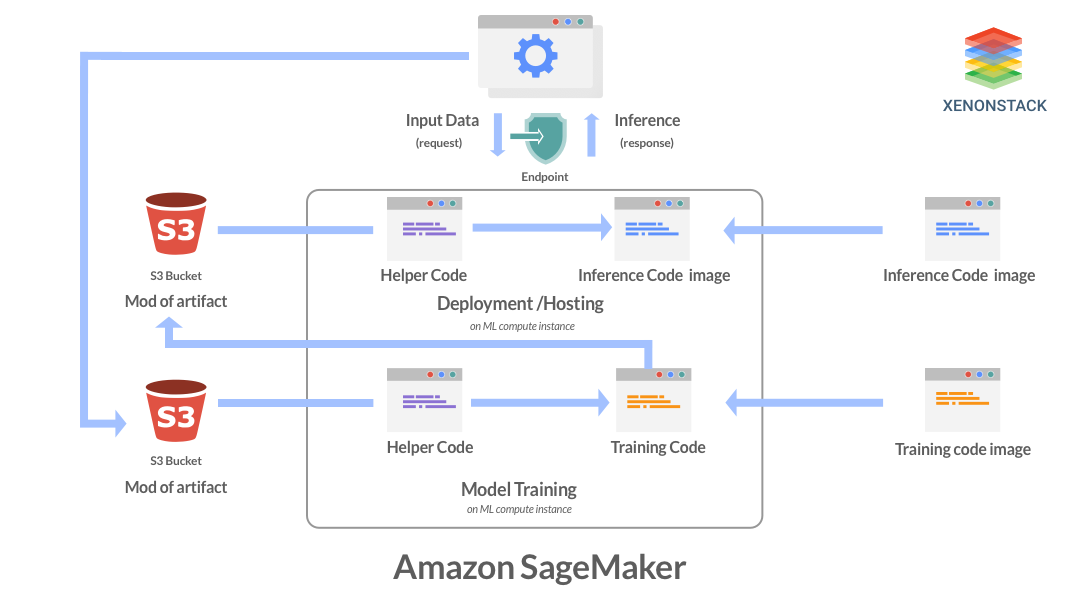
The following is the working training pipeline at Amazon SageMaker:
- First, import the training data from the s3 bucket.
- The training is started by calling the ML to compute instances stored in the EC2 container registry.
- The model artifacts s3 bucket stores the trained model artifacts.
Why is Amazon SageMaker Important?
There are several important features of Amazon SageMaker to streamline the ML workflow. Listed below are the:- Model Evaluation- Evaluating a trained model on SageMaker in two ways: offline testing or online testing. In offline testing, requests are made through Jupyter Notebook's endpoint on historical data (data separated previously) by validation set or using cross-validation. In online testing, the model is deployed, and a traffic threshold is set to handle requests. The traffic threshold is 100% if it is working fine.
- Model Deployment- The model has crossed the baseline, and it’s time to deploy it: the trained model artifacts path and the Docker registry path of the inference code. In SageMaker, the model can be implemented by using
CreateModel API, defining the configuration ofHTTPS endpointand creating it. - Monitoring- The model performance is monitored in real-time, the ground values of data are saved into s3, and the performance deviation is analyzed. This will give the instance where the drift started; then, it is trained on new samples saving in real-time in a bucket.
An advanced tool for building machine solutions, and, as such, should be considered part of the scientific development process. Click to explore about, How Hyperparameter Tuning Works
Data Preparation using SageMaker
A machine learning model depends entirely upon the data. The higher the data quality, the more efficient the model will be. At Amazon SageMaker, the labeling of data is not too difficult. The user can either opt for the private, public, or vendor workforce. In the private and vendor, the user runs the labeling job on its own or uses third-party APIs, and it requires some agreement of confidentiality statements. In the public workforce, a service called Amazon Mechanical Turk Workforce creates a labeling job and gives the status of successful or failed labeled jobs. Below are the steps -- Store data in the s3 bucket and define a manifest file for which the labeling job will run.
- Create a labeled workforce by choosing the workforce type.
- Create a labeling job by choosing the job type, such as Image Classification, Text Classification, Bounding Box, etc.
- For example, the chosen job is a Bounding Box, then draw a bounding box around your desired object and give it a label.
- Visualize your results by seeing the confidence score and other metrics.
What is Hyperparameter Tuning at SageMaker?
Parameters that define the model architecture are Known as hyperparameters, and the process of searching for the ideal model architecture is called hyperparameter tuning. It consists of the following:- Random Search- As the defined list of hyperparameters for the name implies, select the combinations at random, and a training job is run on it. SageMaker provides the concurrent running of jobs for finding the best hyperparameter without interrupting the current training job.
- Bayesian Search- SageMaker has its Bayesian Search algorithm. The algorithm works by checking the performance of previously used combinations of hyperparameters in a job and explores the new combination using the supplied list.
Steps for Hyperparameter Tuning
- For the testing of a training task, the metrics are specified when developing a hyperparameter tuning work. Only 20 criteria can be specified for a single task; the parameters have a unique name with their regular expression to extract information from the logs.
- The defined hyperparameter ranges for the parameter type, i.e., a distinction between the parameter type in the ParameterRanges JSON object.
- Create a notebook on SageMaker and connect with SageMaker’s Boto3 client.
- Specify the bucket and data output location and launch the configured hyperparameter tuning job defined in step A and b.
- Monitor the progress of concurrently running hyperparameter tuning jobs and find the best model on SageMaker’s console by clicking on the best training job.
Amazon SageMaker Best Practices
- Defining the number of parameters: To limit the search space and find the best variables for a model, SageMaker allows the use of 20 parameters in a hyperparameter tuning job.
- Defining the range of hyperparameters: Defining a broader range for hyperparameters allows finding the best possible values, but it is time-consuming. Find the best value by limiting the range of benefits and limiting the search space for that range.
- Logarithmic scaling of hyperparameters: If the search space is small, define hyperparameters' scaling as linear. If the search space is a large opt logarithmic scaling, it decreases the running time of jobs.
- Finding the best number of concurrent training jobs: More work is done quickly in concurrent jobs, but the tuning jobs depend upon the results of previous runs. In other words, running a job can achieve the best results with the least amount of computing time.
- Running training jobs on multiple instances: Running a training job on multiple instances uses the last-reported objective metric. To examine all the parameters, design a distributed training job architecture for getting the logs of the desired metric.
ML pipeline helps to automate ML Workflow and enable the sequence data to be transformed and correlated together in a model to analyzed and achieve outputs. Click to explore about, ML Pipeline Deployment and Architecture
What is Amazon SageMaker Studio?
SageMaker studio is for doing machine learning with a fully functional Integrated Development Environment (IDE). It is a unification of all the key features of SageMaker. In SageMaker Studio, the user can write code in the notebook environment, perform visualization, debugging, model tracking, and monitor the model performance in a single window. It uses the following features of SageMaker.Amazon SageMaker Debugger
The SageMaker debugger will monitor the values of feature vectors and hyperparameters. Store the logs of a debug job in CloudWatch, check the exploding tensors, examine the vanishing gradient problems, and save the tensor values in the s3 bucket. By placingSaveConfig from the debugger SDK at the instance where the value of the tensors needs to be checked and SessionHook will be associated at the start of every debugging job run.
Amazon SageMaker Model Monitor
SageMaker model monitors the model performance by examining the data drift. The defined constraints and statistics file of features are in JSON. Theconstraint.json file contains the list of features with their type, and the required status is defined by the completeness field, whose value ranges from 0-1.
- The file contains the mean, median, quantile, etc., information for each feature. The reports are saved in s3 and can be viewed in detail under
constraint_violations.json, which consists of feature names and type of violation (data type, min or max value of a feature, etc.)Amazon SageMaker Model Experiment
Tracking several experiments (training, hyperparameter tuning jobs, etc.) is easier than SageMaker. Just initialize an Estimator object and log the experiment values. It is possible to import values stored in the experiment into a pandas data frame which makes analysis easier.Amazon SageMaker AutoPilot
ML using AutoPilot is just a click away. Specify the data path and the target attribute(regression, binary classification, or multi-class classification) type. If not specified, the built-in algorithms automatically specify the target type and run the data preprocessing and model according to it. The data preprocessing step automatically generates Python code to use for further jobs. A defined custom pipeline is used for it.DescribeAutoMlJobAPI.The Objective of the Machine learning pipeline is to exercise control over the ML model. Source – Machine Learning Pipeline
Running custom training algorithms
- Run the dockerized training image on SageMaker
- The SageMaker calls a
CreateTrainingJobthe function which runs training for a specific period - Specify the hyperparameters in
TrainingJobName - Check the status by
TrainingJobStatus
Security at SageMaker
- Cloud Security: AWS uses a shared responsibility model, which involves security in the cloud by AWS for securing the infrastructure and security of the cloud, which involves the services opted by a customer, IAM key management, and privileges to different users, keeping the credentials secure, etc.
- Data Security: SageMaker keeps the data and model artifacts encrypted in transit and elsewhere. Requests for a secure (SSL) connection to the Amazon SageMaker API and console. Encrypted notebooks and scripts are using AWS KMS (Key Management Service) Key. If the key is not available, these are encrypted by using the transient key. After the decryption, this transient key becomes obsolete.
What are the advantages of SageMaker?
- It uses a debugger in training that has a specified range of hyperparameters automatically.
- Helps to deploy End-to-end ML pipeline quickly.
- It helps to deploy ML models at the edge using SageMaker Neo.
- ML compute instance suggests the instance type while running the training.
 Our solutions cater to diverse industries with a focus on serving ever-changing marketing needs. Click to explore our Machine Learning Services for Productionizing Models
Our solutions cater to diverse industries with a focus on serving ever-changing marketing needs. Click to explore our Machine Learning Services for Productionizing ModelsConclusion
AWS charges each SageMaker customer for the computation, storage, and data processing tools used to build, train, perform, and log machine learning models and predictions, along with the S3 costs to maintain the data sets used for training and ongoing predictions. The SageMaker framework's design supports ML applications' end-to-end lifecycle, from model data creation to model execution, and the scalable construction also makes it versatile. That means you can use SageMaker independently for model construction, training, or deployment.
- Discover more about MLOps Platform - Productionizing ML Models.
- Click to explore about ML Model Testing Training and Tools.
- Explore more about cloud-managed services to boost IT operations efficiently.


